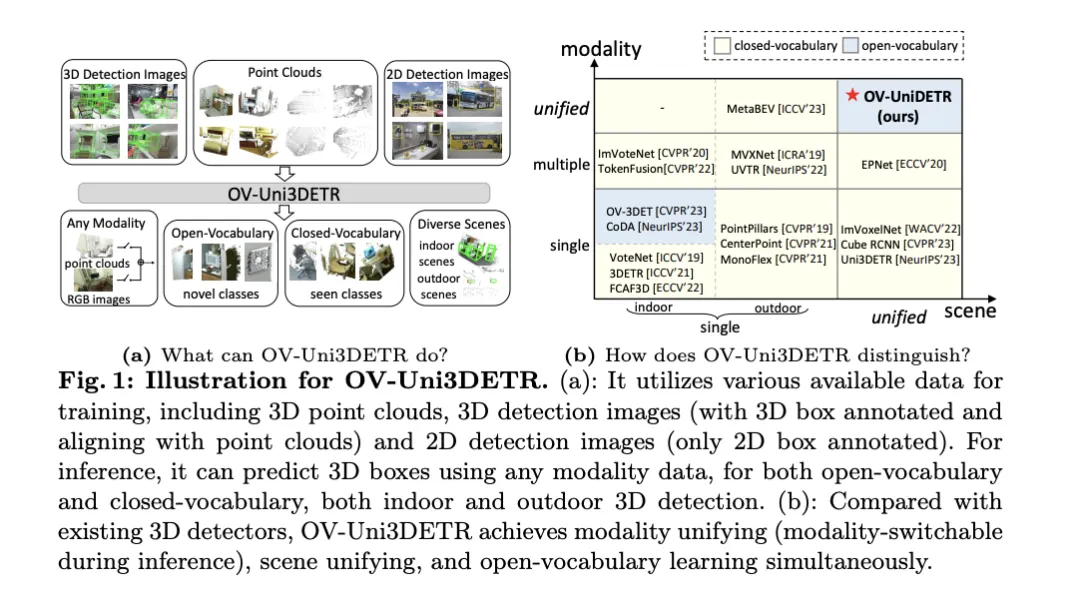
这篇论文讨论了3d目标检测的领域,特别是针对open-vocabulary的3d目标检测。在传统的3d目标检测任务中,系统需要在预测真实场景中物体的定位3d边界框和语义类别标签,这通常依赖于点云或rgb图像。尽管2d目标检测技术因其普遍性和速度展现出色,但相关研究表明,3d通用检测的发展相比之下显得滞后。当前,大多数3d目标检测方法仍依赖于完全监督学习,并受到特定输入模式下完全标注数据的限制,只能识别经过训练过程中出现的类别,无论是在室内还是室外场景。
这篇论文指出,3D通用目标检测面临的挑战主要包括:现有的3D检测器只能在封闭词汇汇总的情况下工作,因此只能检测已经见过的类别。紧迫需要Open-Vocabulary的3D目标检测,以识别和定位训练过程中未获取的新类别目标实例。现有的3D检测数据集在大小和类别上与2D数据集相比都有限制,这限制了在定位新目标方面的泛化能力。此外,3D领域缺乏预训练的图像-文本模型,这进一步加剧了Open-Vocabulary 3D检测的挑战。同时,缺乏一种针对多模态3D检测的统一架构,现有的3D检测器大多设计用于特定的输入模态(点云、RGB图像或二者),这阻碍了有效利用来自不同模态和场景(室内或室外)的有效信息,从而限制了对新目标的泛化能力。
为了解决上述问题,论文提出了一种名为OV-Uni3DETR的统一多模态3D检测器。该检测器在训练期间能够利用多模态和多来源数据,包括点云、具有精确3D框标注的点云和点云对齐的3D检测图像,以及仅包含2D框标注的2D检测图像。通过这种多模态学习方式,OV-Uni3DETR能够在推理时处理任何模态的数据,实现测试时的模态切换,并在检测基础类别和新类别上表现出色。统一的结构进一步促使OV-Uni3DETR能够在室内和室外场景中进行检测,具备Open-Vocabulary能力,从而显著提高3D检测器在类别、场景和模态之间的普适性。
在此外,针对如何泛化检测器以识别新类别的问题,以及如何从没有3D框标注的大量2D检测图像中学习的问题,论文提出了一种称为周期模态传播的方法——通过这种方法,2D和3D模态之间传播知识以解决这两个挑战。通过这种方法,2D检测器的丰富语义知识可以传播到3D领域,以协助发现新的框,并3D检测器的几何知识则可用于在2D检测图像中定位目标,并通过匹配利匹配分类标签。
论文的主要贡献包括提出了一个能够在不同模态和多样化场景中检测任何类别目标的统一Open-Vocabulary 3D检测器OV-Uni3DETR;提出了一个针对室内和室外场景的统一多模态架构;以及提出了2D和3D模态之间知识传播循环的概念。通过这些创新,OV-Uni3DETR在多个3D检测任务上实现了最先进的性能,并在Open-Vocabulary设定下显著超过了之前的方法。这些成果表明,OV-Uni3DETR为3D基础模型的未来发展迈出了重要一步。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
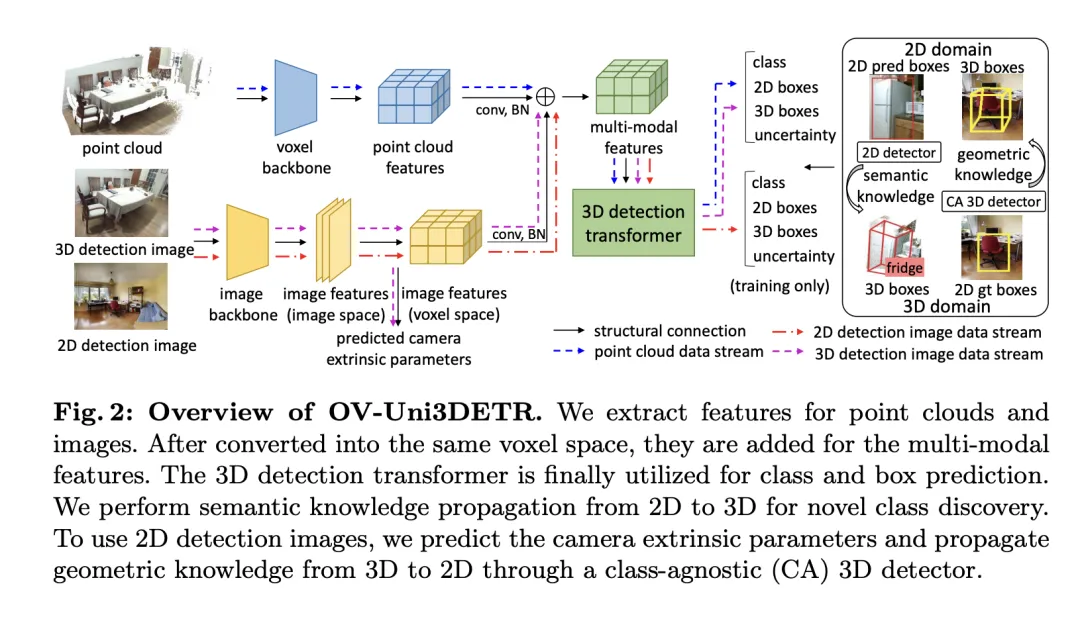
本文介绍了一种多模式学习框架,专门针对3D目标检测任务,通过整合云数据和图像数据来增强检测性能。这种框架能够处理在推理时可能缺失的某些传感器模态,即兼备测验时模态切换的能力。通过特定的网络结构提取并整合来自两种不同模态的特征,包括3D点云特征和2D图像特征,这些特征经过元素化处理和相机参数映射后,被融合用于后续的目标检测任务。
关键的技术点包括使用3D卷积和批量归一化来规范化和整合不同模式的特征,防止在特征级别上的不一致性导致某一模式被忽略。此外,采用随机切换模式的训练策略,确保模型能够灵活地处理只来自单一模式的数据,从而提高模型的鲁棒性和适应性。
最终,该架构利用复合损失函数,结合了类别预测、2D和3D边界框回归的损失,以及一个用于加权回归损失的不确定性预测,来优化整个检测流程。这种多模态学习方法不仅提高了对现有类别的检测性能,而且通过融合不同类型的数据,增强了对新类别的泛化能力。多模态架构最终预测类别标签、4维2D框和7维3D框,用于2D和3D目标检测。对于3D框回归,使用L1损失和解耦IoU损失;对于2D框回归,使用L1损失和GIoU损失。在Open-Vocabulary设置中,存在新类别样本,这增加了训练样本的难度。因此,引入了不确定性预测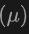 ,并用它来加权L1回归损失。目标检测学习的损失为:
,并用它来加权L1回归损失。目标检测学习的损失为:
对于某些3D场景,可能存在多视图图像,而不是单一的单眼图像。对于它们中的每一个,提取图像特征并使用各自的投影矩阵投影到体素空间。体素空间中的多个图像特征被求和以获取多模态特征。这种方法通过结合来自不同模态的信息,提高了模型对新类别的泛化能力,并增强了在多样化输入条件下的适应性。
在介绍的多模态学习基础上,文中针对Open-Vocabulary的3D检测执行了一种称为“知识传播: ”的方法。Open-Vocabulary学习的核心问题是识别训练过程中未经人工标注的新类别。由于获取点云数据的难度,预训练的视觉-语言模型尚未在点云领域被开发。点云数据与RGB图像之间的模态差异限制了这些模型在3D检测中的性能。
”的方法。Open-Vocabulary学习的核心问题是识别训练过程中未经人工标注的新类别。由于获取点云数据的难度,预训练的视觉-语言模型尚未在点云领域被开发。点云数据与RGB图像之间的模态差异限制了这些模型在3D检测中的性能。

为了解决这个问题,提出利用预训练的2DOpen-Vocabulary检测器的语义知识,并为新类别生成相应的3D边界框。这些生成的3D框将补充训练时可用类别有限的3D真实标签。
具体来说,首先使用2DOpen-Vocabulary检测器生成2D边界框或实例遮罩。考虑到在2D领域可用的数据和标注更为丰富,这些生成的2D框能够实现更高的定位精度,并覆盖更广泛的类别范围。然后,通过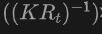 将这些2D框投影到3D空间,以获得相应的3D框。具体操作是使用
将这些2D框投影到3D空间,以获得相应的3D框。具体操作是使用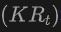
将3D点投影到2D空间,找到2D框内的点,然后对2D框内的这些点进行聚类以消除离群值,从而获得相应的3D框。由于预训练的2D检测器的存在,未标注的新目标可以在生成的3D框集中被发现。通过这种方式,从2D领域到生成的3D框传播的丰富语义知识,极大地促进了3DOpen-Vocabulary检测。对于多视图图像,分别生成3D框并将它们集成在一起以供最终使用。
在推理过程中,当点云和图像都可用时,可以以类似的方式提取3D框。这些生成的3D框也可以视为3DOpen-Vocabulary检测结果的一种形式。将这些3D框添加到多模态3D变换器的预测中,以补充可能缺失的目标,并通过3D非极大值抑制(NMS)过滤重叠的边界框。由预训练的2D检测器分配的置信度得分通过预定的常数系统地除以,然后重新解释为相应3D框的置信度得分。
 Machine Translation
Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

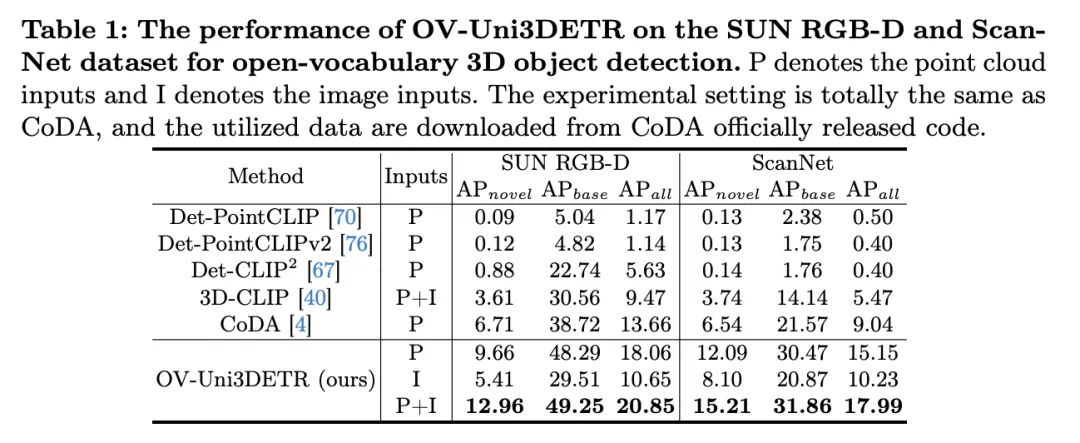
表格展示了OV-Uni3DETR在SUN RGB-D和ScanNet数据集上进行Open-Vocabulary3D目标检测的性能。实验设置与CoDA完全相同,使用的数据来自CoDA官方发布的代码。性能指标包括新类别平均精度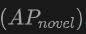 、基类平均精度
、基类平均精度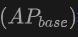 和所有类平均精度
和所有类平均精度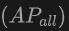 。输入类型包括点云(P)、图像(I)以及它们的组合(P+I)。
。输入类型包括点云(P)、图像(I)以及它们的组合(P+I)。
分析这些结果,我们可以观察到以下几点:
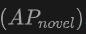 上的提升最为显著。这表明结合点云和图像可以显著提高模型对未见类别的检测能力,以及整体检测性能。
上的提升最为显著。这表明结合点云和图像可以显著提高模型对未见类别的检测能力,以及整体检测性能。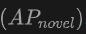 上的表现尤其值得关注,这对于Open-Vocabulary检测尤为关键。在SUN RGB-D数据集上,使用点云和图像输入时的
上的表现尤其值得关注,这对于Open-Vocabulary检测尤为关键。在SUN RGB-D数据集上,使用点云和图像输入时的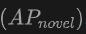 达到了12.96%,在ScanNet数据集上达到了15.21%,这显著高于其他方法,显示了其在识别训练过程中未见过的类别上的强大能力。
达到了12.96%,在ScanNet数据集上达到了15.21%,这显著高于其他方法,显示了其在识别训练过程中未见过的类别上的强大能力。总的来 说,OV-Uni3DETR通过其统一的多模态学习架构,在Open-Vocabulary3D目标检测任务上表现出卓越的性能,尤其是在结合点云和图像数据时,能够有效提升对新类别的检测能力,证明了多模态输入和知识传播策略的有效性和重要性。
说,OV-Uni3DETR通过其统一的多模态学习架构,在Open-Vocabulary3D目标检测任务上表现出卓越的性能,尤其是在结合点云和图像数据时,能够有效提升对新类别的检测能力,证明了多模态输入和知识传播策略的有效性和重要性。
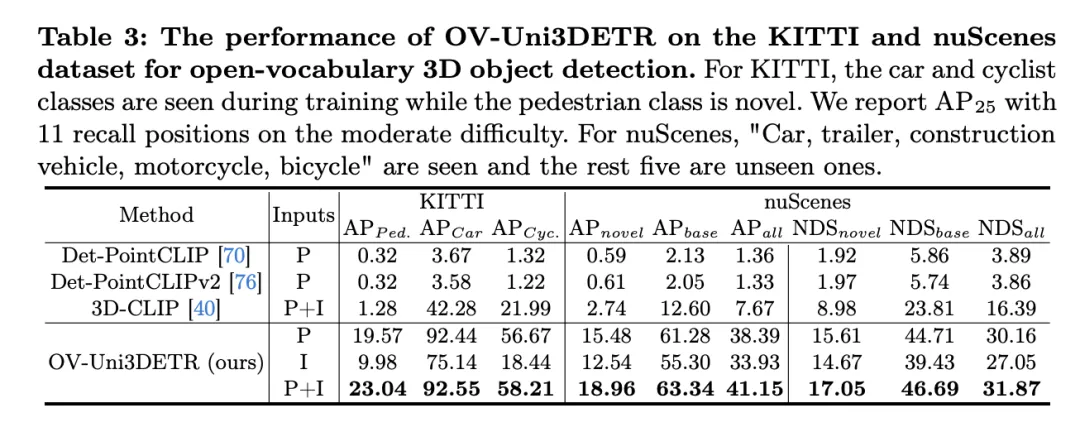
这个表格展示了OV-Uni3DETR在KITTI和nuScenes数据集上进行Open-Vocabulary3D目标检测的性能,涵盖了在训练过程中已见(base)和未见(novel)的类别。对于KITTI数据集,"car"和"cyclist"类别在训练过程中已见,而"pedestrian"类别是新颖的。性能使用在中等难度下的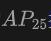
指标来衡量,且采用了11个召回位置。对于nuScenes数据集,"car, trailer, construction vehicle, motorcycle, bicycle"是已见类别,剩余五个为未见类别。除了AP指标外,还报告了NDS(NuScenes Detection Score)来综合评估检测性能。
分析这些结果可以得出以下结论:
OV-Uni3DETR在Open-Vocabulary3D目标检测上展示了卓越的性能,特别是在处理未见类别和多模态数据方面。这些结果验证了多模态输入和知识传播策略的有效性,以及OV-Uni3DETR在提升3D目标检测任务泛化能力方面的潜力。

这篇论文通过提出OV-Uni3DETR,一个统一的多模态3D检测器,为Open-Vocabulary的3D目标检测领域带来了显著的进步。该方法利用了多模态数据(点云和图像)来提升检测性能,并通过2D到3D的知识传播策略,有效地扩展了模型对未见类别的识别能力。在多个公开数据集上的实验结果证明了OV-Uni3DETR在新类别和基类上的出色性能,尤其是在结合点云和图像输入时,能够显著提高对新类别的检测能力,同时在整体检测性能上也达到了新的高度。
优点方面,OV-Uni3DETR首先展示了多模态学习在提升3D目标检测性能中的潜力。通过整合点云和图像数据,模型能够从每种模态中学习到互补的特征,从而在丰富的场景和多样的目标类别上实现更精确的检测。其次,通过引入2D到3D的知识传播机制,OV-Uni3DETR能够利用丰富的2D图像数据和预训练的2D检测模型来识别和定位训练过程中未见过的新类别,这大大提高了模型的泛化能力。此外,该方法在处理Open-Vocabulary检测时显示出的强大能力,为3D检测领域带来了新的研究方向和潜在应用。
缺点方面,虽然OV-Uni3DETR在多个方面展现了其优势,但也存在一些潜在的局限性。首先,多模态学习虽然能提高性能,但也增加了数据采集和处理的复杂性,尤其是在实际应用中,不同模态数据的同步和配准可能会带来挑战。其次,尽管知识传播策略能有效利用2D数据来辅助3D检测,但这种方法可能依赖于高质量的2D检测模型和准确的3D-2D对齐技术,这在一些复杂环境中可能难以保证。此外,对于一些极其罕见的类别,即使是Open-Vocabulary检测也可能面临识别准确性的挑战,这需要进一步的研究来解决。
OV-Uni3DETR通过其创新的多模态学习和知识传播策略,在Open-Vocabulary3D目标检测上取得了显著的进展。虽然存在一些潜在的局限性,但其优点表明了这一方法在推动3D检测技术发展和应用拓展方面的巨大潜力。未来的研究可以进一步探索如何克服这些局限性,以及如何将这些策略应用于更广泛的3D感知任务中。
在本文中,我们主要提出了OV-Uni3DETR,一种统一的多模态开放词汇三维检测器。借助于多模态学习和循环模态知识传播,我们的OV-Uni3DETR很好地识别和定位了新类,实现了模态统一和场景统一。实验证明,它在开放词汇和封闭词汇环境中,无论是室内还是室外场景,以及任何模态数据输入中都有很强的能力。针对多模态环境下统一的开放词汇三维检测,我们相信我们的研究将推动后续研究沿着有希望但具有挑战性的通用三维计算机视觉方向发展。
以上就是多个SOTA !OV-Uni3DETR:提高3D检测在类别、场景和模态之间的普遍性(清华&港大)的详细内容,更多请关注其它相关文章!
# 过程中
# 网站优化课程总结模板
# 巴中优化网站建设哪家好
# 推广营销软件是什么软件
# 关键词排名目标人群
# 装修平台营销推广线上
# 微博营销免费推广
# 惠州网站建设企业名录
# 中山短视频矩阵营销推广方案
# 市场营销策划推广计划书
# 临沂传统行业seo渠道
# 3d
# 提出了
# 未见
# 是在
# 港大
# 多模
# 云和
# 清华
# 模态
# 多个
# 目标检测
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
百度创始人、董事长兼首席执行官李彦宏:AI原生应用比大模型数量更重要
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
生成式人工智能如何改变云安全的游戏规则
OPPO三方联合发布AI可持续发展白皮书,坚持发展健康AI生态
AI时代,企业需要什么样的员工?
实现人工智能和物联网的协同运作
「从未被制造出的最重要机器」,艾伦·图灵及图灵机那些事
华为将于 7 月发布面向 AI 大模型的新款存储产品
鸿蒙智能座舱的AI大模型革新,引领智能座舱领域的变革吗?
参议院司法听证会:AI 不易管控,有可能被恶意分子利用来研发生化武器
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
利好来了,AI再起一波?
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
OpenAI 向所有付费 API 用户开放 GPT-4
借助ChatGPT快速上手ElasticSearch dsl
日本学校探索引入 AI 和无人机:提高安保效率,节省劳动力
微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
看懂AI,找到增长新势能 | 笔记侠AI峰会等你来
报道称亚马逊正在测试AI生成产品评价摘要
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
【趋势周报】全球人工智能产业发展趋势:OpenAI向美国专利局提交“GPT-5”商标申请
石头扫拖机器人 G20 618 福利来袭:4999 元,超值配件领到手软
世界水下机器人大赛:9国青年携手逐梦深蓝
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
开创全新虚拟现实体验的Pimax Crystal VR头显
联想举办2025创新开放日,展出260余项算力及AI产品技术
苹果CEO库克:持续研究生成式人工智能技术
纪录片 《寻找人工智能》全集1080P超清
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
马斯克嘲讽人工智能:机器学习本质就是统计学
在这里见未来!杭州未来科技城全球AI盛会邀您共探最前沿
OpenAI 引入个性化指令功能,消除对话中的重复偏好与信息
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
轻量级的深度学习框架Tinygrad
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
CREATOR制造、使用工具,实现LLM「自我进化」
利用AI探索抗体“钥匙”、加速药物研发——访百图生科团队
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
OpenAI CEO 山姆・阿尔特曼呼吁 AI 领域中美应当合作
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
ChatGPT设计出的第一个机器人来了!【附人工智能行业预测】
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
国内首款大尺寸仿鸵双足机器人“大圣”亮相,穿戴红色战袍
人工智能如何用于家庭安全
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
2024-04-11

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
