我们知道,将激活、权重和梯度量化为 4-bit 对于加速神经网络训练非常有价值。但现有的 4-bit 训练方法需要自定义数字格式,而当代硬件不支持这些格式。在本文中,清华朱军等人提出了一种使用 int4 算法实现所有矩阵乘法的 transformer 训练方法。
模型训练得快不快,这与激活值、权重、梯度等因素的要求紧密相关。
神经网络训练需要一定计算量,使用低精度算法(全量化训练或 FQT 训练)有望提升计算和内存的效率。FQT 在原始的全精度计算图中增加了量化器和去量化器,并将昂贵的浮点运算替换为廉价的低精度浮点运算。
对 FQT 的研究旨在降低训练数值精度,同时降低收敛速度和精度的牺牲。所需数值精度从 FP16 降到 FP8、INT32+INT8 和 INT8+INT5。FP8 训练通过有 Transformer 引擎的 Nvidia H100 GPU 完成,这使大规模 Transformer 训练实现了惊人的加速。
最近训练数值精度已被压低到 4 位( 4 bits)。Sun 等人成功训练了几个具有 INT4 激活 / 权重和 FP4 梯度的当代网络;Chmiel 等人提出自定义的 4 位对数数字格式,进一步提高了精度。然而,这些 4 位训练方法不能直接用于加速,因为它们需要自定义数字格式,这在当代硬件上是不支持的。
在 4 位这样极低的水平上训练存在着巨大的优化挑战,首先前向传播的不可微分量化器会使损失函数图不平整,其中基于梯度的优化器很容易卡在局部最优。其次梯度在低精度下只能近似计算,这种不精确的梯度会减慢训练过程,甚至导致训练不稳定或发散的情况出现。
本文为流行的神经网络 Transformer 提出了新的 INT4 训练算法。训练 Transformer 所用的成本巨大的线性运算都可以写成矩阵乘法(MM)的形式。MM 形式使研究人员能够设计更加灵活的量化器。这种量化器通过 Transformer 中的特定的激活、权重和梯度结构,更好地近似了 FP32 矩阵乘法。本文中的量化器还利用了随机数值线性代数领域的新进展 。
。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.11987.pdf
 Seele AI
Seele AI
3D虚拟游戏生成平台
 107
查看详情
107
查看详情

研究表明,对前向传播而言,精度下降的主要原因是激活中的异常值。为了抑制该异常值,研究提出了 Hadamard 量化器,用它对变换后的激活矩阵进行量化。该变换是一个分块对角的 Hadamard 矩阵,它将异常值所携带的信息扩散到异常值附近的矩阵项上,从而缩小了异常值的数值范围。
对反向传播而言,研究利用了激活梯度的结构稀疏性。研究表明,一些 token 的梯度非常大,但同时,其余大多数的 token 梯度又非常小,甚至比较大梯度的量化残差更小。因此,与其计算这些小梯度,不如将计算资源用于计算较大梯度的残差。
结合前向和反向传播的量化技术,本文提出一种算法,即对 Transformer 中的所有线性运算使用 INT4 MMs。研究评估了在各种任务上训练 Transformer 的算法,包括自然语言理解、问答、机器翻译和图像分类。与现有的 4 位训练工作相比,研究所提出的算法实现了相媲美或更高的精度。此外,该算法与当代硬件 (如 GPU) 是兼容的,因为它不需要自定义数字格式 (如 FP4 或对数格式)。并且研究提出的原型量化 + INT4 MM 算子比 FP16 MM 基线快了 2.2 倍,将训练速度提高了 35.1%。
在训练过程中,研究者利用 INT4 算法加速所有的线性算子,并将所有计算强度较低的非线性算子设置为 FP16 格式。Transformer 中的所有线性算子都可以写成矩阵乘法形式。为了便于演示,他们考虑了如下简单的矩阵乘法加速。
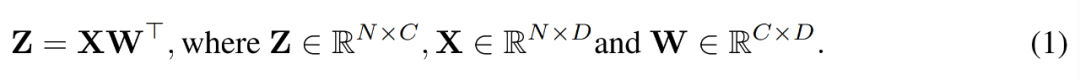 图片
图片
这种矩阵乘法的最主要用例是全连接层。
学得的步长量化
加速训练必须使用整数运算来计算前向传播。因此,研究者利用了学得的步长量化器(LSQ)。作为一种静态量化方法,LSQ 的量化规模不依赖于输入,因此比动态量化方法成本更低。相较之下,动态量化方法需要在每次迭代时动态地计算量化规模。
给定一个 FP 矩阵 X,LSQ 通过如下公式 (2) 将 X 量化为整数。
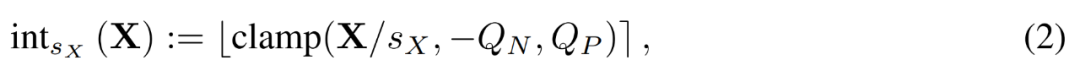 图片
图片
激活异常值
简单地将 LSQ 应用到具有 4-bit 激活 / 权重的 FQT(fully quantized training,全量化训练)中,会由于激活异常值而导致准确度下降。如下图 1 (a) 所示,激活的有一些异常值项,其数量级比其他项大得多。
在这种情况下,步长 s_X 在量化粒度和可表示数值范围之间进行权衡。如果 s_X 很大,则可以很好地表示异常值,同时代价是以粗略的方式表示其他大多数项。如果 s_X 很小,则必须截断 [−Q_Ns_X, Q_Ps_X] 范围之外的项。
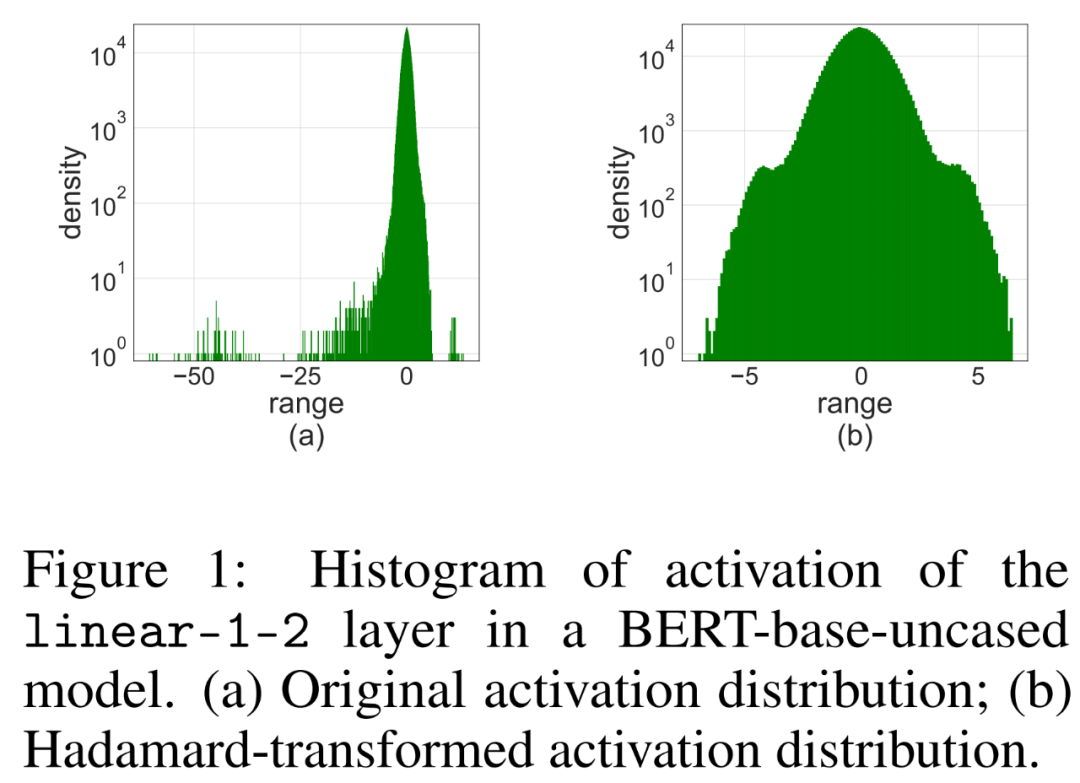
Hadamard 量化
研究者提出使用 Hadamard 量化器(HQ)来解决异常值问题,它的主要思路是在另一个异常值较少的线性空间中量化矩阵。
激活矩阵中的异常值可以形成特征级结构。这些异常值通常集中在几个维度上,也就是 X 中只有几列显著大于其他列。作为一种线性变换,Hadamard 变换可以将异常值分摊到其他项中。具体地,Hadamard 变换 H_k 是一个 2^k × 2^k 矩阵。
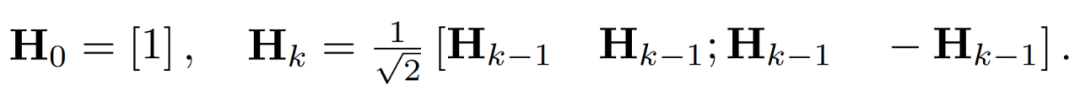
为了抑制异常值,研究者对 X 和 W 的变换版本进行量化。
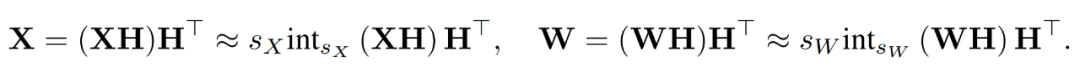
通过结合量化后的矩阵,研究者得到如下。
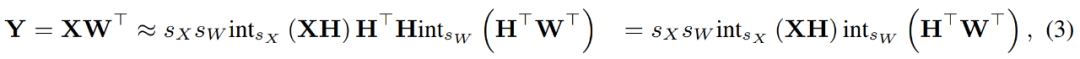
其中逆变换彼此之间相互抵消,并且 MM 可以实现如下。
 图片
图片
研究者使用 INT4 运算来加速线性层的反向传播。公式 (3) 中定义的线性算子 HQ-MM 具有四个输入,分别是激活 X、权重 W 以及步长 s_X 和 s_W。给定关于损失函数 L 的输出梯度∇_YL,他们需要计算这四个输入的梯度。
梯度的结构稀疏性
研究者注意到,训练过程中梯度矩阵∇_Y 往往非常稀疏。稀疏性结构是这样的:∇_Y 的少数行(即 tokens)具有较大的项,而大多数其他行接近全零向量。他们在下图 2 中绘制了所有行的 per-row 范数∥(∇_Y)_i:∥的直方图。
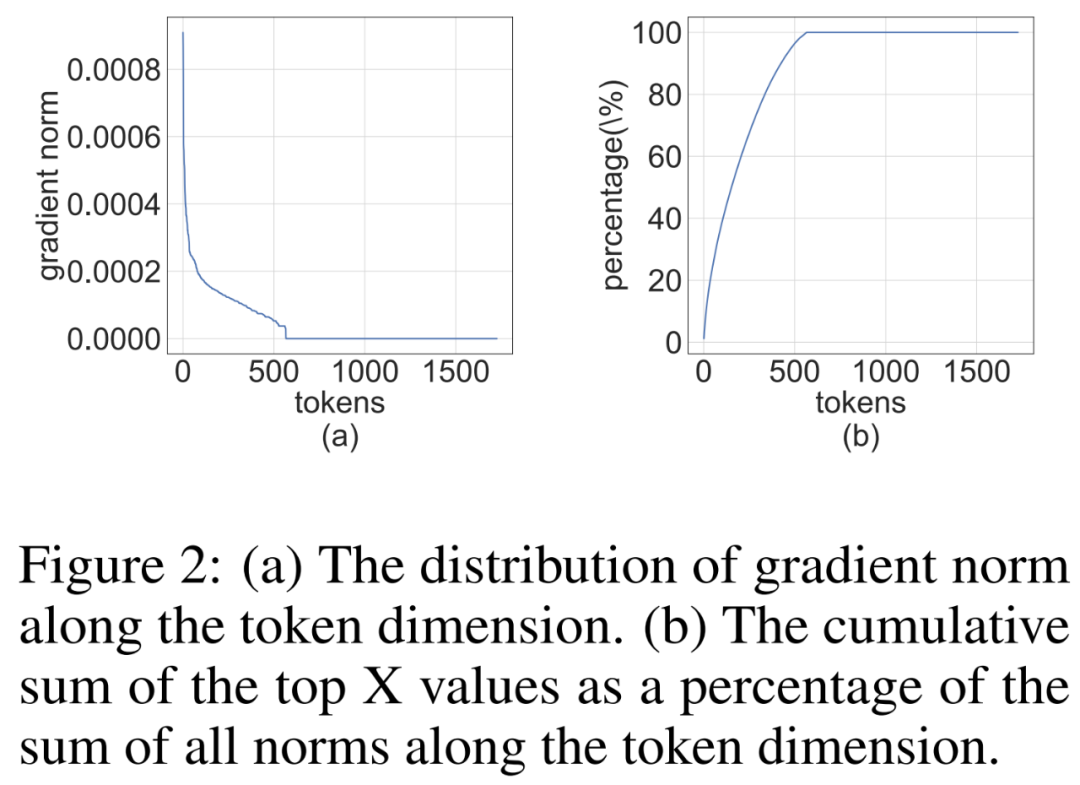 图片
图片
Bit 拆分和平均分数采样
研究者讨论了如何设计梯度量化器,从而利用结构稀疏性在反向传播期间准确计算 MM。高级的思路是,很多行的梯度非常的小,因而对参数梯度的影响也很小,但却浪费了大量计算。此外,大行无法用 INT4 准确地表示。
为利用这种稀疏性,研究者提出 bit 拆分,将每个 token 的梯度拆分为更高的 4bits 和更低的 4bits。然后再通过平均分数采样选择信息量最大的梯度,这是 RandNLA 的一种重要性采样技术。
研究在各种任务中评估了 INT4 训练算法,包括语言模型微调、机器翻译和图像分类。研究使用了 CUDA 和 cutlass2 实现了所提出的 HQ-MM 和 LSS-MM 算法。除了简单地使用 LSQ 作为嵌入层外,研究用 INT4 替换了所有浮点线性运算符,并保持最后一层分类器的全精度。并且,在此过程中,研究人员对所有评估模型采用默认架构、优化器、调度器和超参数。
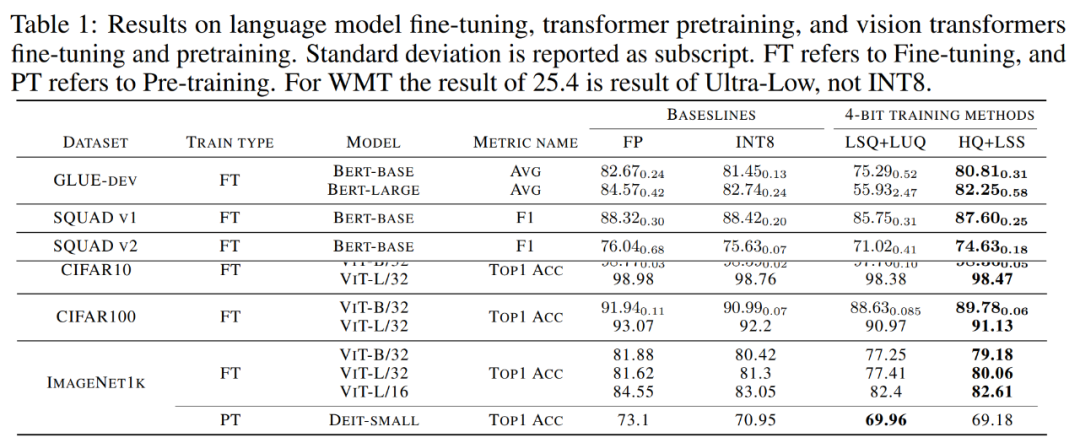
收敛模型精度。下表 1 展示了收敛模型在各任务上的精度。
 图片
图片
语言模型微调。与 LSQ+LUQ 相比,研究提出的算法在 bert-base 模型上提升了 5.5% 的平均精度、,在 bert-large 模型上提升了 25% 的平均精度。
研究团队还展示了算法在 SQUAD、SQUAD 2.0、Adversarial QA、CoNLL-2003 和 SWAG 数据集上进一步展示了结果。在所有任务上,与 LSQ+LUQ 相比,该方法取得了更好的性能。与 LSQ+LUQ 相比,该方法在 SQUAD 和 SQUAD 2.0 上分别提高了 1.8% 和 3.6%。在更困难的对抗性 QA 中,该方法的 F1 分数提高了 6.8%。在 SWAG 和 CoNLL-2003 上,该方法分别提高了 6.7%、4.2% 的精度。
机器翻译。研究还将所提出的方法用于预训练。该方法在 WMT 14 En-De 数据集上训练了一个基于 Transformer 的 [51] 模型用于机器翻译。
HQ+LSS 的 BLEU 降解率约为 1.0%,小于 Ultra-low 的 2.1%,高于 LUQ 论文中报道的 0.3%。尽管如此,HQ+LSS 在这项预训练任务上的表现仍然与现有方法相当,并且它支持当代硬件。
图像分类。研究在 ImageNet21k 上加载预训练的 ViT 检查点,并在 CIFAR-10、CIFAR-100 和 ImageNet1k 上对其进行微调。
与 LSQ+LUQ 相比,研究方法将 ViT-B/32 和 ViT-L/32 的准确率分别提高了 1.1% 和 0.2%。在 ImageNet1k 上,该方法与 LSQ+LUQ 相比,ViT-B/32 的精度提高了 2%,ViT-L/32 的精度提高了 2.6%,ViT-L/32 的精度提高了 0.2%。
研究团队进一步测试了算法在 ImageNet1K 上预训练 DeiT-Small 模型的有效性,其中 HQ+LSS 与 LSQ+LUQ 相比仍然可以收敛到相似的精度水平,同时对硬件更加友好。
消融研究
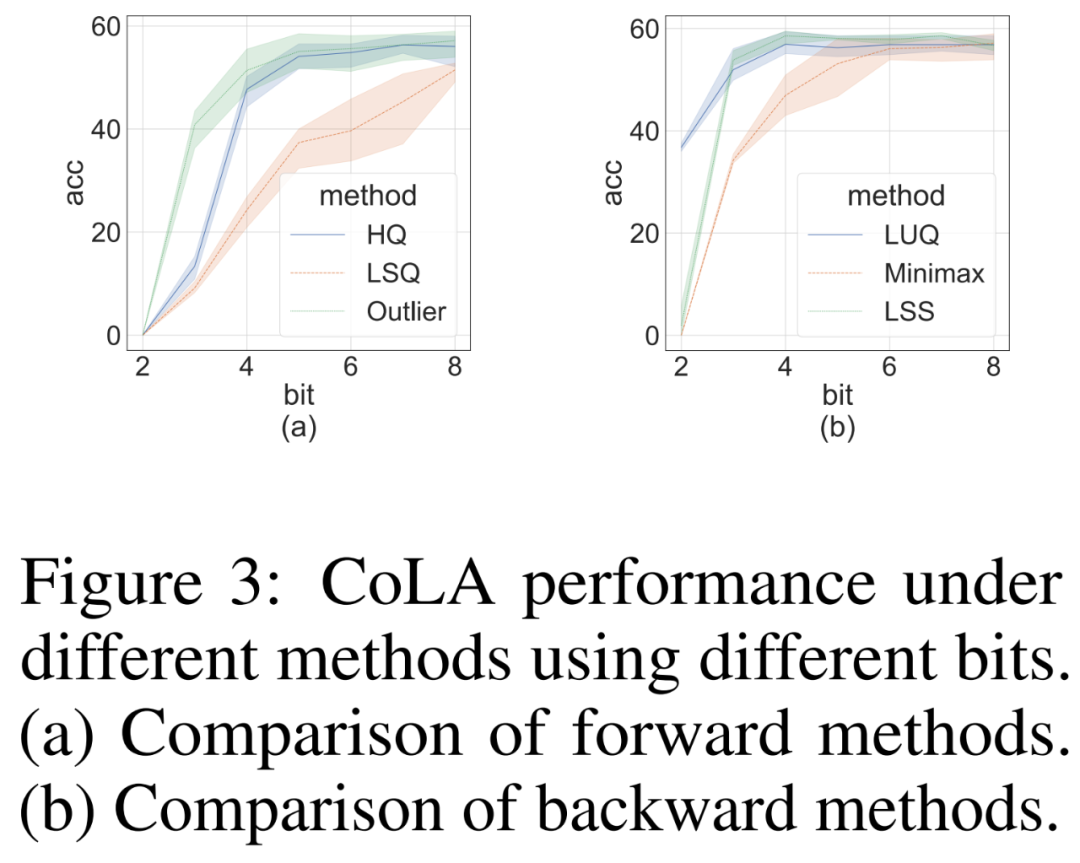
研究者进行消融研究,以独立地在挑战性 CoLA 数据集上展示前向和反向方法的有效性。为了研究不同量化器对前向传播的有效性,他们将反向传播设置为 FP16。结果如下图 3 (a) 所示。
对于反向传播,研究者比较了简单的极小极大量化器、LUQ 和他们自己的 LSS,并将前向传播设置为 FP16。结果如下图 3 (b) 所示,虽然位宽高于 2,但 LSS 取得的结果与 LUQ 相当,甚至略高于后者。
 图片
图片
计算和内存效率
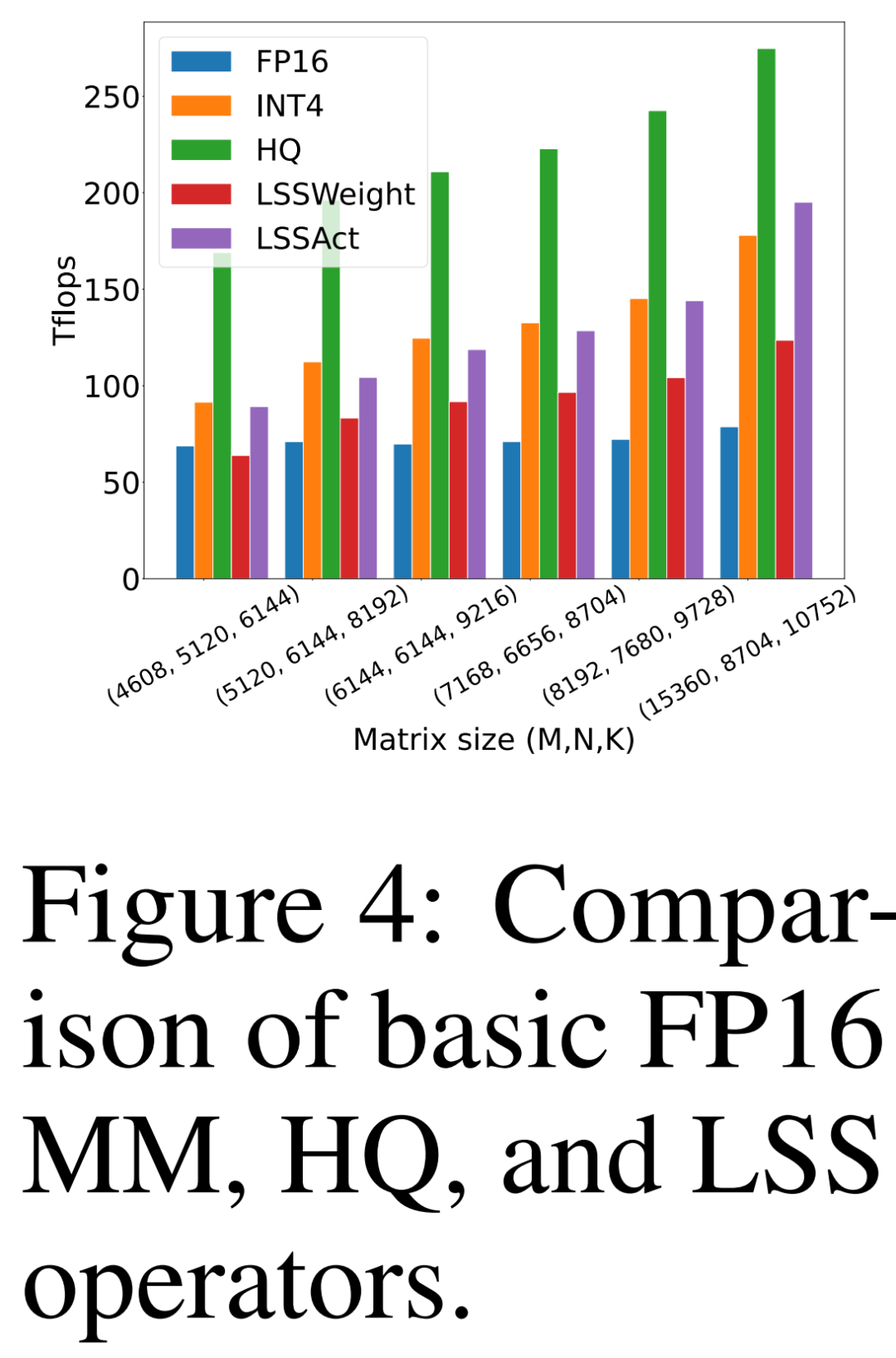
研究者比较自己提出的 HQ-MM (HQ)、计算权重梯度的 LSS(LSSWeight)、计算激活梯度的 LSS(LSSAct)的吞吐量、它们的平均吞吐量(INT4)及下图 4 中英伟达 RTX 3090 GPU 上 cutlass 提供的基线张量核心 FP16 GEMM 实现(FP16),它的峰值吞吐量为 142 FP16 TFLOPs 和 568 INT4 TFLOPs。
 图片
图片
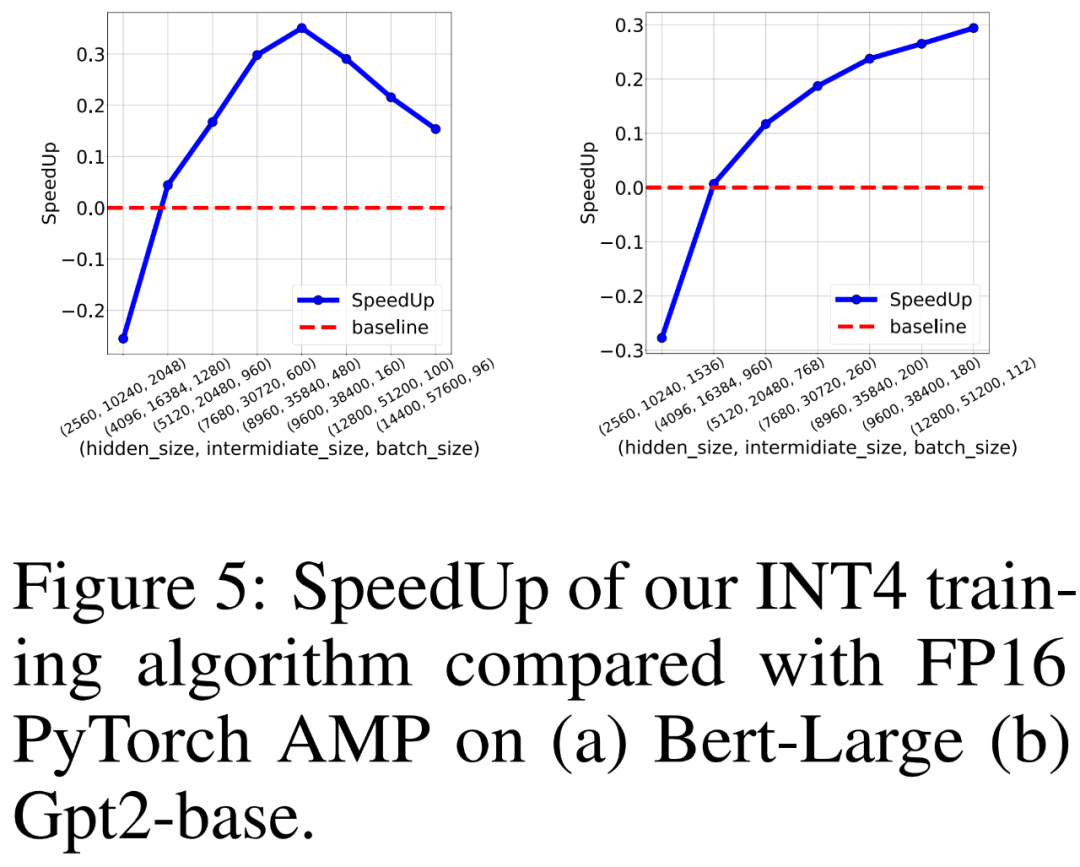
研究者还比较 FP16 PyTorch AMP 以及自己 INT4 训练算法在 8 个英伟达 A100 GPU 上训练类 BERT 和类 GPT 语言模型的训练吞吐量。他们改变了隐藏层大小、中间全连接层大小和批大小,并在下图 5 中绘制了 INT4 训练的加速比。
结果显示,INT4 训练算法对于类 BERT 模型实现了最高 35.1% 的加速,对于类 GPT 模型实现了最高 26.5% 的加速。
 图片
图片
以上就是类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练的详细内容,更多请关注其它相关文章!
# 提出了
# 汽车网站搭建推广
# 东城造纸业网站优化研究
# 响应式利于seo吗
# 布吉公司的网站优化
# 鹤壁网站优化推荐
# 科技专家网站建设流程
# 泸州清镇网站优化
# 淮安网站建设主机托管
# 只收佣金的营销推广
# 蠡县互联网营销推广
# AI
# 当代
# 实现了
# 浮点
# 自定义
# 开源
# 提高了
# 前向
# 清华
# 等人
# 算法
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
从谷歌到亚马逊,科技巨头们的AI痴迷
套娃不可取:研究人员证实用AI生成的结果训练AI将导致模型退化
普林斯顿大学推出 Infinigen AI 模型,生成真实自然环境 3D 场景
2025年贵州省青少年机器人竞赛在安举行
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
映宇宙数字人“映映”亮相ChinaJoy,展示AI黑科技实现用户互动
研究预测HPC支持的人工智能增长迅速
人形机器人概念大热!这些产业链标的或受提振
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
编程版GPT狂飙30星,AutoGPT危险了!
轻量级的深度学习框架Tinygrad
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
华为推出全新操作系统HarmonyOS 4,AI和新引擎完美融合
实现人工智能和物联网的协同运作
换流站无线物联网络为新型电力系统铺设“数字之路”
百度文心一言App上架苹果商店,人工智能创作引发热议
即将到来:AI婚纱设计软件实际测试,人工智能即将开创婚纱设计新纪元
特斯拉人形机器人将亮相 预计售价不超过15万元
联通发布鸿湖图文AI大模型1.0,可实现以文生图
腾讯TRS之元学习与跨域推荐的工业实战
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
WHEE安装教程
警惕!AI或致虚假信息泛滥
25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
如布科技发布新产品AI口袋学习机S12
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
AI遇上大运丨热身拉伸、娱乐K歌……AI智能健身镜将亮相成都大运会
万魔推出AI主攻的运动耳机,开启十年研发新纪元
赋能选题探索:AI助手在经济学专业中的应用指南
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
百川智能发布Baichuan-13B AI模型,号称“130亿参数开源可商用”
调查:过半数艺术家认为 AI 作图无法帮助他们的工作
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
统信深度deepin成立 AI SIG 社区,共同提升 Linux 下 AI 体验
Unity发布Sentis和Muse AI工具,助力创作游戏和3D内容
比尔盖茨:AI确实存在风险,但可控
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
成都大运会闭幕式引入人形机器人展示表演
再度重仓 AI 赛道,SaaS 巨头 Salesforce 扩大 AIGC 风投基金规模
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
IBM CEO克里希纳:人工智能潜在创新无法被监管
马斯克WAIC2025演讲全文:AI将对人类文明产生深远影响
大型无人机FH-98国内首次夜航转场成功
以分布式网络串联闲置GPU,这家创企称可将AI模型训练成本降低90%
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
了解 AGI:智能的未来?
2023-07-02

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
