国内高校打造类Sora模型VDT,通用视频扩散Transformer被ICLR 2025接收
2 月 16 日,OpenAI Sora 的发布无疑标志着视频生成领域的一次重大突破。Sora 基于 Diffusion Transformer 架构,和市面上大部分主流方法(由 2D Stable Diffusion 扩展)并不相同。为什么 Sora 坚持使用 Diffusion Transformer,其中的原因从同时期发表在 ICLR 2025(VDT: General-purpose Video Diffusion Transformers via Mask Modeling)的论文可以窥见一二。这项工作由中国人民大学研究团队主导,并与加州大学伯克利分校、香港大学等进行了合作,最早于 2025 年 5 月公开在 arXiv 网站。研究团队提出了基于 Transformer 的 Video 统一生成框架 - Video Diffusion Transformer (VDT),并对采用 Transformer 架构的原因给出了详细的解释。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

- 论文标题:VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- 文章地址:Openreview: https://openreview.net/pdf?id=Un0rgm9f04
- arXiv地址: https://arxiv.org/abs/2305.13311
- 项目地址:VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- 代码地址:https://github.com/RERV/VDT
研究者表示,采用 Transformer 架构的 VDT 模型,在视频生成领域的优越性体现在:
- 与主要为图像设计的 U-Net 不同,Transformer 能够借助其强大的 token 化和注意力机制,捕捉长期或不规则的时间依赖性,从而更好地处理时间维度。
- 只有当模型学习(或记忆)了世界知识(例如空间时间关系和物理法则)时,才能生成与现实世界相符的视频。因此,模型的容量成为视频扩散的一个关键组成部分。Transformer 已经被证明具有高度的可扩展性,比如 PaLM 模型就拥有高达 540B 的参数,而当时最大的 2D U-Net 模型大小仅 2.6B 参数(SDXL),这使得 Transformer 比 3D U-Net 更适合应对视频生成的挑战。
- 视频生成领域涵盖了包括无条件生成、视频预测、插值和文本到图像生成等多项任务。以往的研究往往聚焦于单一任务,常常需要为下游任务引入专门的模块进行微调。此外,这些任务涉及多种多样的条件信息,这些信息在不同帧和模态之间可能有所不同,这就需要一个能够处理不同输入长度和模态的强大架构。Transformer 的引入能够实现这些任务的统一。
- 将 Transformer 技术应用于基于扩散的视频生成,展现了 Transformer 在视频生成领域的巨大潜力。VDT 的优势在于其出色的时间依赖性捕获能力,能够生成时间上连贯的视频帧,包括模拟三维对象随时间的物理动态。
- 提出统一的时空掩码建模机制,使 VDT 能够处理多种视频生成任务,实现了技术的广泛应用。VDT 灵活的条件信息处理方式,如简单的 token 空间拼接,有效地统一了不同长度和模态的信息。同时,通过与该工作提出的时空掩码建模机制结合,VDT 成为了一个通用的视频扩散工具,在不修改模型结构的情况下可以应用于无条件生成、视频后续帧预测、插帧、图生视频、视频画面补全等多种视频生成任务。
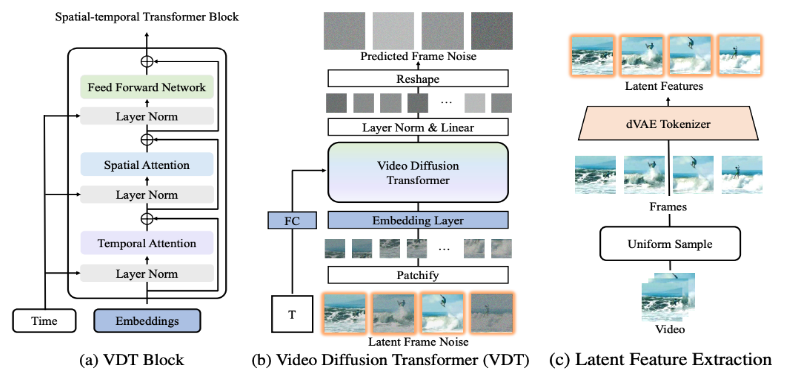
VDT 框架与 Sora 的框架非常相似,包括以下几部分:输入 / 输出特征。VDT 的目标是生成一个 F×H×W×3 的视频片段,由 F 帧大小为 H×W 的视频组成。然而,如果使用原始像素作为 VDT 的输入,尤其是当 F 很大时,将导致计算量极大。为解决这个问题,受潜在扩散模型(LDM)的启发,VDT 使用预训练的 VAE tokenizer 将视频投影到潜在空间中。将输入和输出的向量维度减少到潜在特征 / 噪声的 F×H/8×W/8×C,加速了 VDT 的训练和推理速度,其中 F 帧潜在特征的大小为 H/8×W/8。这里的 8 是 VAE tokenizer 的下采样率,C 表示潜在特征维度。线性嵌入。遵循 Vision Transformer 的方法,VDT 将潜在视频特征表示划分为大小为 N×N 的非重叠 Patch。时空 Transformer Block。受到视频建模中时空自注意力成功的启发,VDT 在 Transformer Block 中插入了一个时间注意力层,以获得时间维度的建模能力。具体来说,每个 Transformer Block 由一个多头时间注意力、一个多头空间注意力和一个全连接前馈网络组成,如上图所示。对比 Sora 最新发布的技术报告,可以看到 VDT 和 Sora 在实现细节上仅存在一些细微差别。首先,VDT 采用的是在时空维度上分别进行注意力机制处理的方法,而 Sora 则是将时间和空间维度合并,通过单一的注意力机制来处理。这种分离注意力的做法在视频领域已经相当常见,通常被视为在显存限制下的一种妥协选择。VDT 选择采用分离注意力也是出于计算资源有限的考虑。Sora 强大的视频动态能力可能来自于时空整体的注意力机制。其次,不同于 VDT,Sora 还考虑了文本条件的融合。之前也有基于 Transformer 进行文本条件融合的研究(如 DiT),这里猜测 Sora 可能在其模块中进一步加入了交叉注意力机制,当然,直接将文本和噪声拼接作为条件输入的形式也是一种潜在的可能。在 VDT 的研究进程中,研究者将 U-Net 这个常用的基础骨干网络替换为 Transformer。这不仅验证了 Transformer 在视频扩散任务中的有效性,展现了便于扩展和增强连续性的优势,也引发了他们对于其潜在价值的进一步思考。随着 GPT 模型的成功和自回归(AR)模型的流行,研究者开始探索 Transformer 在视频生成领域的更深层次应用,思考其是否能为实现视觉智能提供新的途径。视频生成领域有一个与之密切相关的任务 —— 视频预测。将预测下一个视频帧作为通往视觉智能的路径这一想法看似简单,但它实际上是许多研究者共同关注的问题。基于这一考虑,研究者希望在视频预测任务上进一步适配和优化他们的模型。视频预测任务也可以视为条件生成,这里给定的条件帧是视频的前几帧。VDT 主要考虑了以下三种条件生成方式: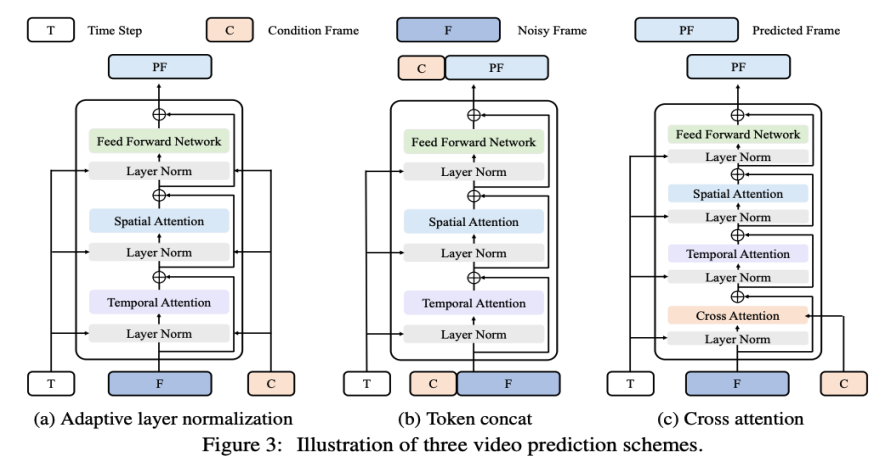
自适应层归一化。实现视频预测的一种直接方法是将条件帧特征整合到 VDT Block 的层归一化中,类似于我们如何将时间信息整合到扩散过程中。交叉注意力。研究者还探索了使用交叉注意力作为视频预测方案,其中条件帧用作键和值,而噪声帧作为查询。这允许将条件信息与噪声帧融合。在进入交叉注意力层之前,使用 VAE tokenizer 提取条件帧的特征并 Patch 化。同时,还添加了空间和时间位置嵌入,以帮助我们的 VDT 学习条件帧中的对应信息。Token 拼接。VDT 模型采用纯粹的 Transformer 架构,因此,直接使用条件帧作为输入 token 对 VDT 来说是更直观的方法。研究者通过在 token 级别拼接条件帧(潜在特征)和噪声帧来实现这一点,然后将其输入到 VDT 中。接下来,他们将 VDT 的输出帧序列分割,并使用预测的帧进行扩散过程,如图 3 (b) 所示。研究者发现,这种方案展示了最快的收敛速度,与前两种方法相比,在最终结果上提供了更优的表现。此外,研究者发现即使在训练过程中使用固定长度的条件帧,VDT 仍然可以接受任意长度的条件帧作为输入,并输出一致的预测特征。在 VDT 的框架下,为了实现视频预测任务,不需要对网络结构进行任何修改,仅需改变模型的输入即可。这一发现引出了一个直观的问题:我们能否进一步利用这种可扩展性,将 VDT 扩展到更多样化的视频生成任务上 —— 例如图片生成视频 —— 而无需引入任何额外的模块或参数。通过回顾 VDT 在无条件生成和视频预测中的功能,唯一的区别在于输入特征的类型。具体来说,输入可以是纯噪声潜在特征,或者是条件和噪声潜在特征的拼接。然后,研究者引入了 Unified Spatial-Temporal Mask Modeling 来统一条件输入,如下图 4 所示: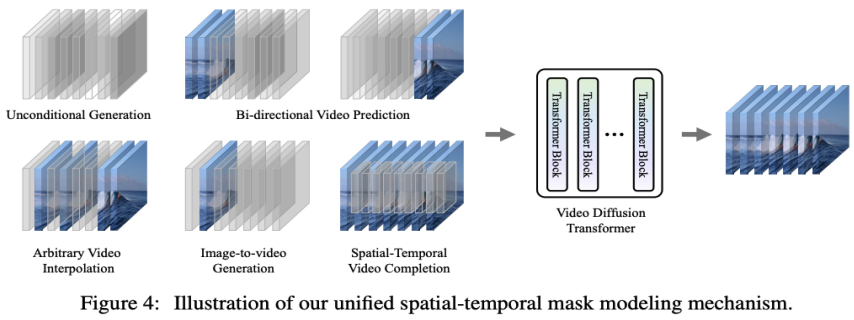
通过上述方法,VDT 模型不仅可以无缝地处理无条件视频生成和视频预测任务,还能够通过简单地调整输入特征,扩展到更广泛的视频生成领域,如视频帧插值等。这种灵活性和可扩展性的体现,展示了 VDT 框架的强大潜力,为未来的视频生成技术提供了新的方向和可能性。

Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情
 有趣的是,除 text-to-video 外,OpenAI 也展示了 Sora 非常惊艳的其他任务,包括基于 image 生成,前后 video predict 以及不同 video clip 相融合的例子等,和研究者提出的 Unified Spatial-Temporal Mask Modeling 所支持的下游任务非常相似;同时在参考文献中也引用了 kaiming 的 MAE。所以,这里猜测 Sora 大概率底层也使用了类 MAE 的训练方法。研究者同时探索了生成模型 VDT 对简单物理规律的模拟。他们在 Physion 数据集上进行实验,VDT 使用前 8 帧作为条件帧,并预测接下来的 8 帧。在第一个示例(顶部两行)和第三个示例(底部两行)中,VDT 成功模拟了物理过程,包括一个沿抛物线轨迹运动的球和一个在平面上滚动并与圆柱体碰撞的球。在第二个示例(中间两行)中,VDT 捕捉到了球的速度 / 动量,因为球在碰撞圆柱体前停了下来。这证明了 Transformer 架构是可以学习到一定的物理规律。
有趣的是,除 text-to-video 外,OpenAI 也展示了 Sora 非常惊艳的其他任务,包括基于 image 生成,前后 video predict 以及不同 video clip 相融合的例子等,和研究者提出的 Unified Spatial-Temporal Mask Modeling 所支持的下游任务非常相似;同时在参考文献中也引用了 kaiming 的 MAE。所以,这里猜测 Sora 大概率底层也使用了类 MAE 的训练方法。研究者同时探索了生成模型 VDT 对简单物理规律的模拟。他们在 Physion 数据集上进行实验,VDT 使用前 8 帧作为条件帧,并预测接下来的 8 帧。在第一个示例(顶部两行)和第三个示例(底部两行)中,VDT 成功模拟了物理过程,包括一个沿抛物线轨迹运动的球和一个在平面上滚动并与圆柱体碰撞的球。在第二个示例(中间两行)中,VDT 捕捉到了球的速度 / 动量,因为球在碰撞圆柱体前停了下来。这证明了 Transformer 架构是可以学习到一定的物理规律。
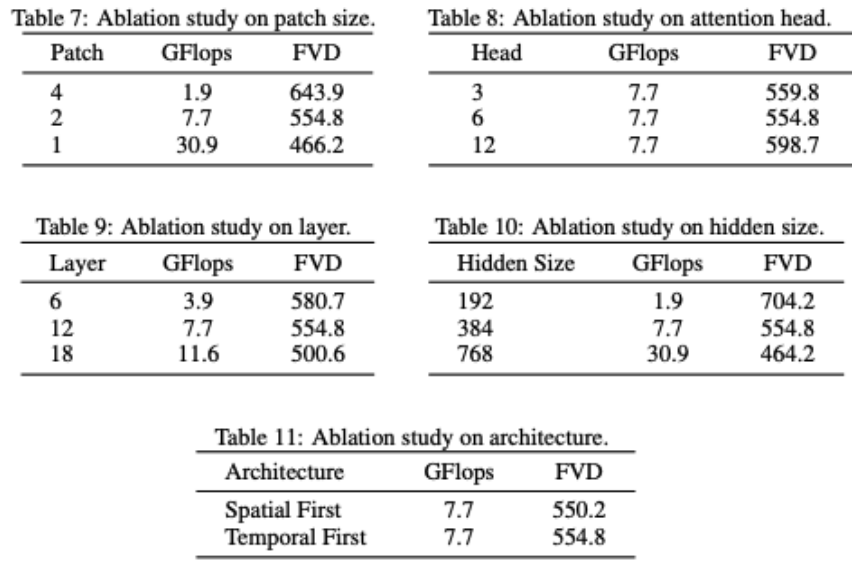
VDT 对网络结构进行部分消融。可以发现模型性能和 GFlops 强相关,模型结构本身的一些细节反而影响不是很大,这个和 DiT 的发现也是一致的。研究者还对 VDT 模型进行了一些结构上的消融研究。结果表明,减小 Patchsize、增加 Layers 的数量以及增大 Hidden Size 都可以进一步提高模型的性能。Temporal 和 Spatial 注意力的位置以及注意力头的数量对模型的结果影响不大。在保持相同 GFlops 的情况下,需要一些设计上的权衡,总体而言,模型的性能没有显著差异。但是,GFlops 的增加会带来更好的结果,这展示了 VDT 或者 Transformer 架构的可扩展性。VDT 的测试结果证明了 Transformer 架构在处理视频数据生成方面的有效性和灵活性。由于计算资源的限制,VDT 只在部分小型学术数据集上进行了实验。我们期待未来研究能够在 VDT 的基础上,进一步探索视频生成技术的新方向和应用,也期待中国公司能早日推出国产 Sora 模型。以上就是国内高校打造类Sora模型VDT,通用视频扩散Transform er被ICLR 2025接收的详细内容,更多请关注其它相关文章!
er被ICLR 2025接收的详细内容,更多请关注其它相关文章!
# 产业
# 网站导航优化
# 日立网站建设公司排名
# 宝达seo
# 之处
# 展示了
# 进行了
# 两行
# 几个
# 所示
# 万字
# 这一
# 开源
# 国内
# stable diffusion
# sora
# openai
# 网站建设迁移方案
# 禄劝商业营销推广方案
# 网站建设 手机网站
# 9090电影网站建设
# 城阳区网站建设平台招标
# 网站SEO优化b就用迅捷云排名
# 网站建设的主要工作
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
消息称 ChatGPT 未来有望增加更多功能:上传文件分析信息,还能记住用户画像
马斯克回应“人工智能让一切变得更好”:我们已经是半机器人了
组建团队,字节跳动要造机器人?
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
报告称 70% 程序员已使用各种 AI 工具编程
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
剧透!蜜小豆@2025世界人工智能大会多个亮点曝光
懒人必备的家居清洁好物,石头自清洁扫拖机器人G20
陈丹琦ACL学术报告来了!详解大模型「*」数据库7大方向3大挑战,3小时干货满满
从GOXR到PartyOn,XRSPACE致力打造多元共赢的元宇宙世界
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
OpenAI大神Karpathy最新分享:为什么OpenAI内部对AI Agents最感兴趣
塑造全能智能管家:华为小艺AI加成应对大模型挑战
OpenAI CEO 阿尔特曼到访日本,对全球 AI 协调合作表示乐观
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
机构:边缘AI或是当前预期差最大的AI方向
猿编程参加人工智能高峰论坛,推动人工智能教育解决方案在千所学校推行
推动企业数字化转型升级!“松江智造”摘世界人工智能大会重磅奖项
AI智能室内效果图设计软件效果,确实惊到我了!
华为AI大模型将融入HarmonyOS 4
美妆行业在AI时代蓬勃发展
“上海市民营企业人工智能赋能创新中心”揭牌成立
如何对员工进行再培训以充分利用供应链管理中的人工智能创新
美图第二届影像节发布七款AI影像创作工具
全球首款AI裸眼3D平板 国产的售价破万
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
警惕!AI或致虚假信息泛滥
MiracleVision视觉大模型
今年,全球客服中心支出将增长 16.2%,迎接对话式 AI 的浪潮,根据 Gartner 报告
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
联想创投携手12家被投企业MWC展示元宇宙、机器人等技术
网友自制 AI 版《流浪地球 3》预告片,登上 CCTV6
实现人工智能和物联网的协同运作
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
MIT开发“PhotoGuard”技术保护图像免遭恶意AI编辑
小岛秀夫不反对使用AI 但认为人类应该凌驾于AI
GPT-4最全攻略来袭!OpenAI官方发布,六个月攒下来的使用经验都在里面了
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
让AI助手带您轻松愉快地享受写作之旅
有 ARM 和 X86 两个版本,香橙派游戏掌机细节曝光
AI工具助力公司实施每周4.5天工作制,带来巨大效益
PHP和OpenCV库:如何实现人脸识别
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
2025世界人工智能大会(上海)开幕式纪要
鸿蒙4即将支持大规模AI模型
2024-02-26
 er被ICLR 2025接收的详细内容,更多请关注其它相关文章!
er被ICLR 2025接收的详细内容,更多请关注其它相关文章!
