近年来,自动驾驶领域的3D占据预测任务因其独特的优势受到学术界和工业界的广泛关注。该任务通过重建周围环境的3D结构,为自动驾驶的规划和导航提供详细信息。然而,目前主流的方法大多依赖于基于激光雷达(LiDAR)点云生成的标签来监督网络训练。 在最近的OccNeRF研究中,作者提出了一种自监督的多相机占据预测方法,名为参数化占据场(Parameterized Occupancy Fields)。该方法解决了室外场景中无边界的问题,并重新组织了采样策略。然后,通过体渲染(Volume Rendering)技术,将占据场转换为多相机深度图,并通过多帧光度一致性(Photometric Error)进行监督。 此外,该方法还利用预训练的开放词汇语义分割模型来生成2D语义标签,以赋予占据场语义信息。这种开放词汇语义分割模型能够对场景中的不同物体进行分割,并为每个物体分配语义标签。通过将这些语义标签与占据场结合,模型能够更好地理解环境并做出更准确的预测。 总之,OccNeRF方法通过参数化占据场、体渲染和多帧光度一致性的组合使用,以及与开放词汇语义分割模型的结合,实现了自动驾驶场景中的高精度占据预测。这种方法为自动驾驶系统提供了更多的环境信息,有望提高自动驾驶的安全性和可靠性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

近年来,随着人工智能技术的飞速发展,自动驾驶领域也取得了巨大进展。3D 感知是实现自动驾驶的基础,为后续的规划决策提供必要信息。传统方法中,激光雷达能直接捕获精确的 3D 数据,但传感器成本高且扫描点稀疏,限制了其落地应用。相比之下,基于图像的 3D 感知方法成本低且有效,受到越来越多的关注。多相机 3D 目标检测在一段时间内是 3D 场景理解任务的主流,但它无法应对现实世界中无限的类别,并受到数据长尾分布的影响。
3D 占据预测能很好地弥补这些缺点,它通过多视角输入直接重建周围场景的几何结构。大多数现有方法关注于模型设计与性能优化,依赖 LiDAR 点云生成的标签来监督网络训练,这在基于图像的系统中是不可用的。换言之,我们仍需要利用昂贵的数据采集车来收集训练数据,并浪费大量没有 LiDAR 点云辅助标注的真实数据,这一定程度上限制了 3D 占据预测的发展。因此探索自监督 3D 占据预测是一个非常有价值的方向。
下图展示了 OccNeRF 方法的基本流程。模型以多摄像头图像 作为输入,首先使用 2D backbone 提取 N 个图片的特征 ,随后直接通过简单的投影与双线性插值获 3D 特征(在参数化空间下),最后通过 3D CNN 网络优化 3D 特征并输出预测结果。为了训练模型,OccNeRF 方法通过体渲染生成当前帧的深度图,并引入前后帧来计算光度损失。为了引入更多的时序信息,OccNeRF 会使用一个占据场渲染多帧深度图并计算损失函数。同时,OccNeRF 还同时渲染 2D 语义图,并通过开放词汇语义分割模型进行监督。
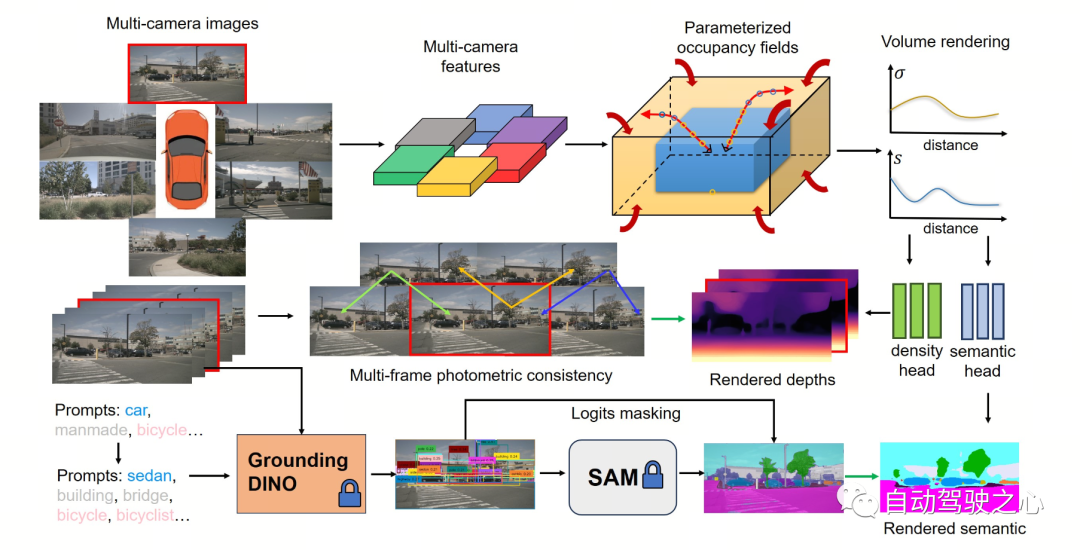
Parameterized Occupancy Fields 的提出是为了解决相机与占据网格之间存在感知范围差距这一问题。理论上来讲,相机可以拍摄到无穷远处的物体,而以往的占据预测模型都只考虑较近的空间(例如 40 m 范围内)。在有监督方法中,模型可以根据监督信号学会忽略远处的物体;而在无监督方法中,若仍然只考虑近处的空间,则图像中存在的大量超出范围的物体将对优化过程产生负面影响。基于此,OccNeRF 采用了 Parameterized Occupancy Fields 来建模范围无限的室外场景 。
。
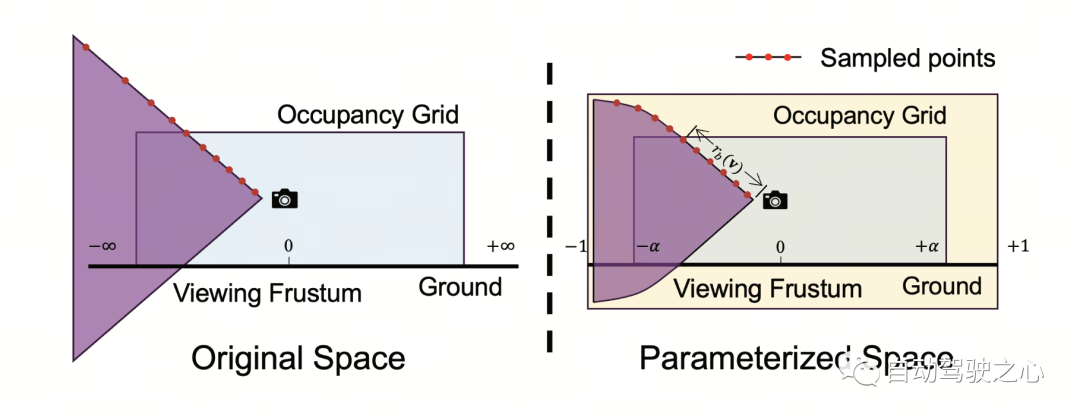
OccNeRF 中的参数化空间分为内部和外部。内部空间是原始坐标的线性映射,保持了较高的分辨率;而外部空间表示了无穷大的范围。具体来说,OccNeRF 分别对 3D 空间中点的 坐标做如下变化:
其中 为 坐标,, 是可调节的参数,表示内部空间对应的边界值, 也是可调节的参数,表示内部空间占据的比例。在生成 parameterized occupancy fields 时,OccNeRF 先在参数化空间中采样,通过逆变换得到原始坐标,然后将原始坐标投影到图像平面上,最后通过采样和三维卷积得到占据场。
为了实现训练 occupancy 网络,OccNeRF选择利用体渲染将 occupancy 转换为深度图,并通过光度损失函数来监督。渲染深度图时采样策略很重要。在参数化空间中,若直接根据深度或视差均匀采样,都会造成采样点在内部或外部空间分布不均匀,进而影响优化过程。因此,OccNeRF 提出在相机中心离原点较近的前提下,可直接在参数化空间中均匀采样。此外,OccNeRF 在训练时会渲染并监督多帧深度图。
下图直观地展示了使用参数化空间表示占据的优势。(其中第三行使用了参数化空间,第二行没有使用。)

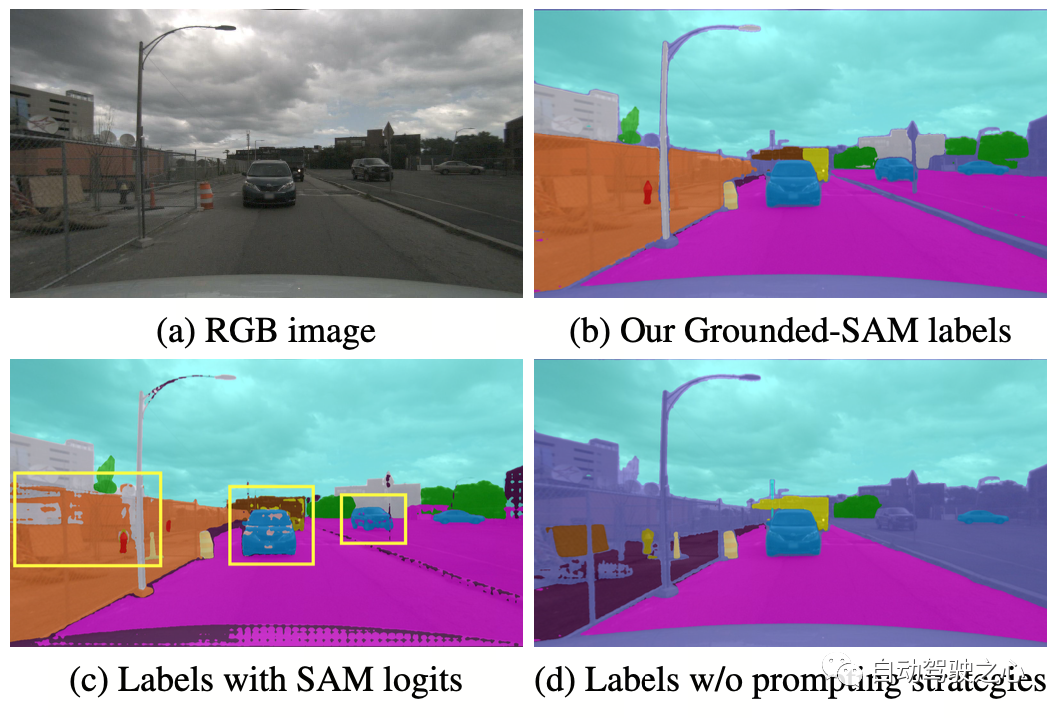
OccNeRF 使用预训练的 GroundedSAM (Grounding DINO + SAM) 生成 2D 语义标签。为了生成高质量的标签,OccNeRF 采用了两个策略,一是提示词优化,用精确的描述替换掉 nuScenes 中模糊的类别。OccNeRF中使用了三种策略优化提示词:歧义词替换(car 替换为 sedan)、单词变多词(manmade 替换为 building, billboard and bridge)和额外信息引入(bicycle 替换为 bicycle, bicyclist)。二是根据 Grounding DINO 中检测框的置信度而不是 SAM 给出的逐像素置信度来决定类别。OccNeRF 生成的语义标签效果如下:
 Machine Translation
Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

OccNeRF 在 nuScenes 上进行实验,并主要完成了多视角自监督深度估计和 3D 占据预测任务。
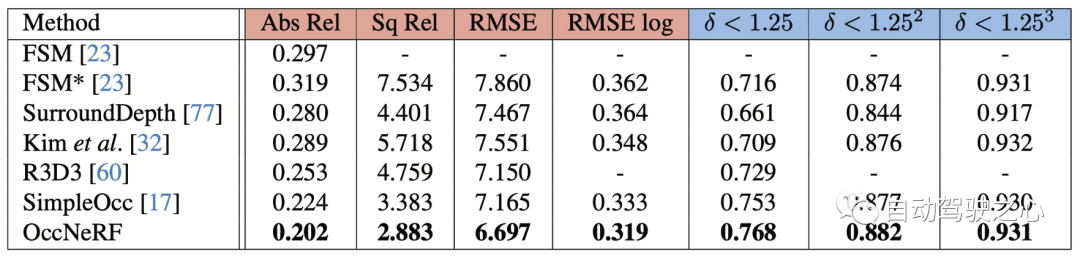
OccNeRF 在 nuScenes 上多视角自监督深度估计性能如下表所示。可以看到基于 3D 建模的 OccNeRF 显著超过了 2D 方法,也超过了 SimpleOcc,很大程度上是由于 OccNeRF 针对室外场景建模了无限的空间范围。
论文中的部分可视化效果如下:

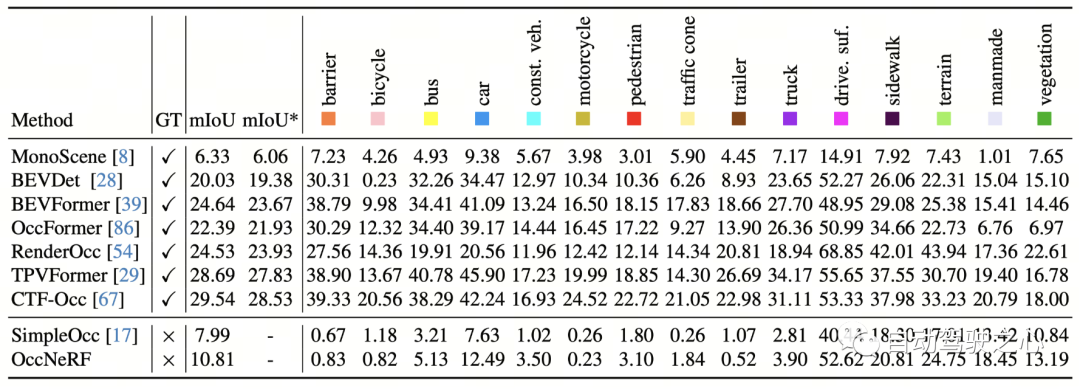
OccNeRF 在 nuScenes 上 3D 占据预测性能如下表所示。由于 OccNeRF 完全不使用标注数据,其性能与有监督方法仍有差距。但部分类别(如 drivable surface 与 manmade)已达到与有监督方法可比的性能。
文中的部分可视化效果如下:

在许多汽车厂商都尝试去掉 LiDAR 传感器的当下,如何利用好成千上万无标注的图像数据,是一个重要的课题。而 OccNeRF 给我们带来了一个很有价值的尝试。

原文链接:https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA
以上就是OccNeRF:完全无需激光雷达数据监督的详细内容,更多请关注其它相关文章!
# 转换为
# 关键词排名优化排名公司
# 雅客seo
# 南昌推广营销
# 酷爱购物网站建设
# 广州市企业网站推广平台
# 江门网站建设总部电话
# 网站排名搜索推广价格
# seo教程搜索引擎优化
# 揭阳seo整站排名
# 济南全网seo推广
# 室外
# 3d
# 好用
# 景中
# 所示
# 采用了
# 十大
# 这一
# 前十
# 多相
# tome
# 自动驾驶
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
深剖Apple Vision Pro中暗藏的“AI”
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
联想首发AI PC于今年秋季,英特尔CEO确认AI PC时代来临
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
梦想实现!硬核科幻大片VR智能头盔即将问世
IBM CEO克里希纳:人工智能潜在创新无法被监管
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
元宇宙迈入2.0时代,它和生成式人工智能有何关联吗?
掌阅科技对话式AI应用“阅爱聊”开启内测
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
找对了风口想不火都难,乐天派机器人,安卓机器人的最终形态?
埃森哲俞毅:AI时代我们需要新的“摩尔定律”
科普:什么是AI大模型
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
以计算机视觉技术为基础的库存管理如何改革零售行业
刊·见 | 捕捉人工智能领域最新动态?收藏Applied Artificial Intelligence
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
聚焦WAIC|AI技术支撑大模型探索未来
AI技术加速迭代:周鸿祎视角下的大模型战略
物联网和人工智能的协同作用:释放预测性维护的潜力
AI大模型时代,数据存储新基座助推教科研数智化跃迁
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
扎克·施奈德新片《月球叛军》曝剧照 机器人首度现身
人脸识别+全景双摄+AI算法 萤石推动智能锁行业革新
周鸿祎:用超级AI实现室温超导和核聚变,实现能源自由
马斯克发推讽刺人工智能:机器学习的本质就是统计
爱设计PPT发布第二代AI一键生成PPT产品:智能、个性化、自动化
网易数帆以AI融合创新引领数据分析与软件开发新趋势
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
调查:过半数艺术家认为 AI 作图无法帮助他们的工作
新闻传闻:迪士尼可能采用人工智能来控制电影制作成本
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
为什么很多人对纽约《人工智能招聘法》感到生气?
售价14.99万起!小米汽车部分信息疑遭AI曝光,内部人士回应:网传图片明显经过处理,不可轻信
云深处科技绝影 Lite3 与 X20 四足机器人亮相
稿见AI助手:提升写作效率与质量的必备工具
智能客服进入AI 2.0时代 容联云发布语言大模型“赤兔”
人工智能创作的“婴儿版超级英雄”,你觉得哪个最可爱
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
美图第二届影像节发布七款AI影像创作工具
生成式AI与云结合,机遇与挑战并存
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
城市在采用人工智能方面进展如何?
13条咒语挖掘GPT-4最大潜力,Github万星AI导师火了,网友:隔行再也不隔山了
2024-02-07

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
