通过对齐三维形状、二维图片以及相应的语言描述,多模态预训练方法也带动了3D表征学习的发展。
不过现有的多模态预训练框架收集数据的方法缺乏可扩展性,极大限制了多模态学习的潜力,其中最主要的瓶颈在于语言模态的可扩展性和全面性。
最近,Salesforce AI联手斯坦福大学和得克萨斯大学奥斯汀分校,发布了ULIP(CVP R2025)和ULIP-2项目,这些项目正在引领3D理解的新篇章。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/pdf/2212.05171.pdf
论文链接:https://arxiv.org/pdf/2305.08275.pdf
代码链接:https://github.com/salesforce/ULIP
研究人员采用了独特的方法,使用3D点云、图像和文本进行模型的预训练,将它们对齐到一个统一的特征空间。这种方法在3D分类任务中取得了最先进的结果,并为跨领域任务(如图像到3D检索)开辟了新的可能性。
并且ULIP-2将这种多模态预训练变得可以不需要任何人工标注,从而可以大规模扩展。
ULIP-2在ModelNet40的下游零样本分类上取得了显著的性能提升,达到74.0%的最高准确率;在现实世界的ScanObjectNN基准上,仅用140万个参数就获得了91.5%的总体准确率,标志着在无需人类3D标注的可扩展多模态3D表示学习方面的突破。
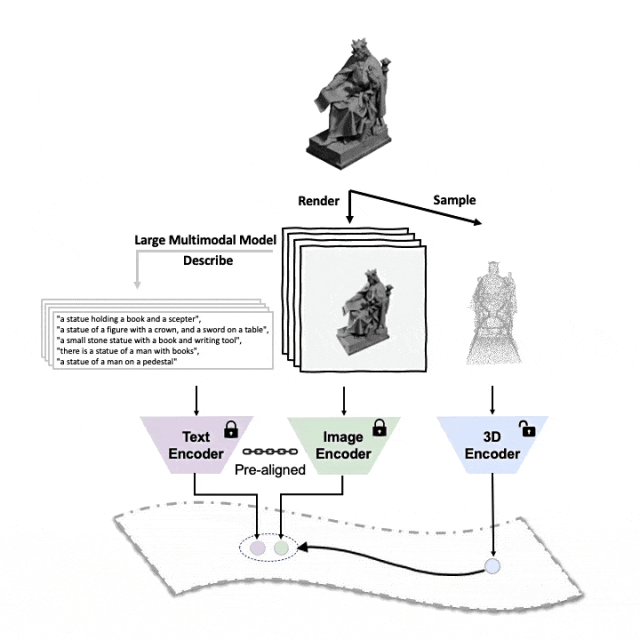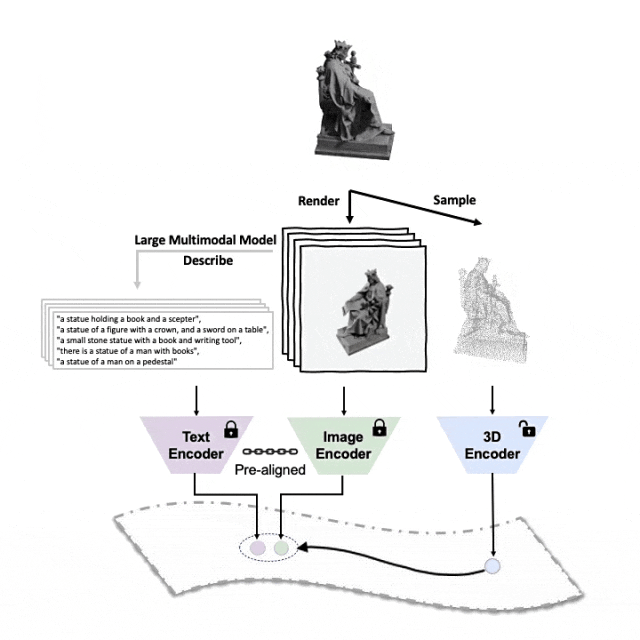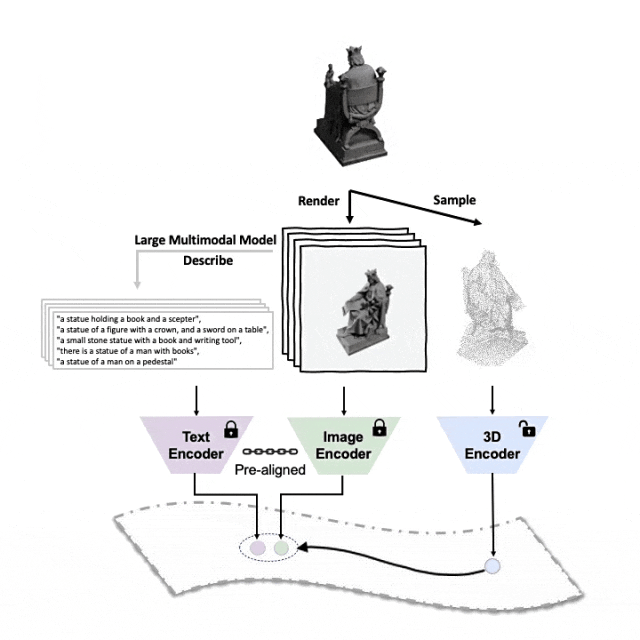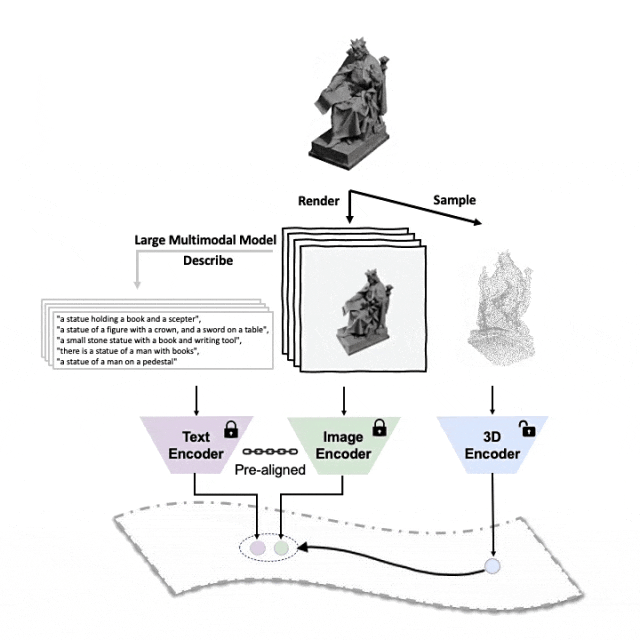
对齐(3D,图像,文本)这三种特征的预训练框架示意图
代码以及发布的大规模tri-modal的数据集(「ULIP - Obj*erse Triplets」和「ULIP - ShapeNet Triplets」)已经开源。
3D理解是人工智能领域的重要组成部分,它让机器能像人类一样在三维空间中感知和互动。这种能力在自动驾驶汽车、机器人、虚拟现实和增强现实等领域都有着重要的应用。
然而,由于3D数据的处理和解释复杂性,以及收集和注释3D数据的成本,3D理解一直面临着巨大的挑战。
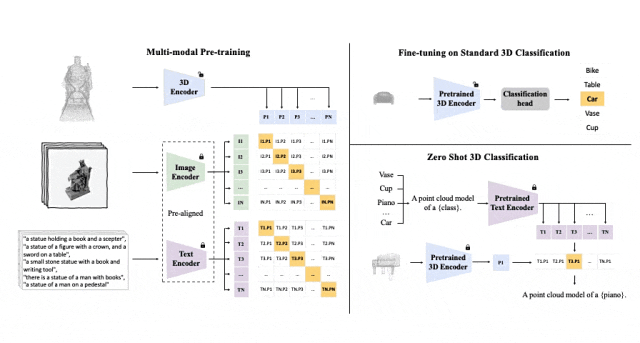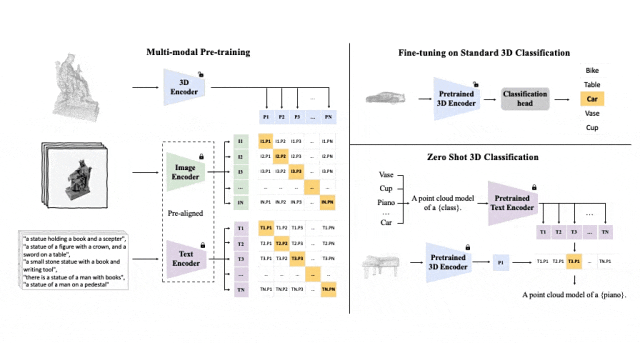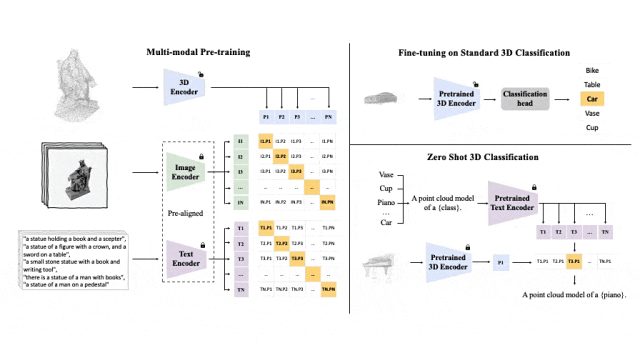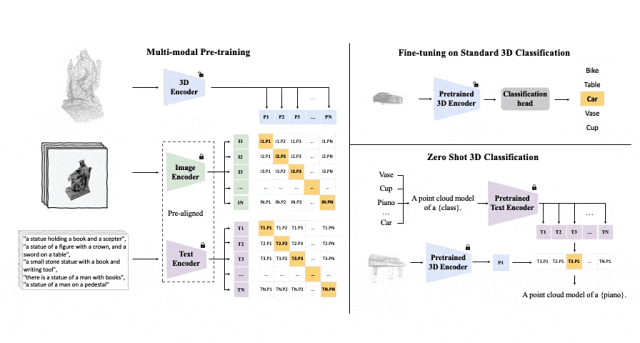
Tri-modal 预训练框架以及其下游任务
ULIP(已经被CVPR2025接收)采用了一种独特的方法,使用3D点云、图像和文本进行模型的预训练,将它们对齐到一个统一的表示空间。
这种方法在3D分类任务中取得了最先进的结果,并为跨领域任务(如图像到3D检索)开辟了新的可能性。
ULIP的成功关键在于使用预先对齐的图像和文本编码器,如CLIP,它在大量的图像-文本对上进行预训练。
这些编码器将三种模态的特征对齐到一个统一的表示空间,使模型能够更有效地理解和分类3D对象。
这种改进的3D表示学 习不仅增强了模型对3D数据的理解,而且还使得跨模态应用如zero-shot 3D分类和图像到3D检索成为可能,因为3D编码器获得了多模态上下文。
习不仅增强了模型对3D数据的理解,而且还使得跨模态应用如zero-shot 3D分类和图像到3D检索成为可能,因为3D编码器获得了多模态上下文。
ULIP的预训练损失函数如下:
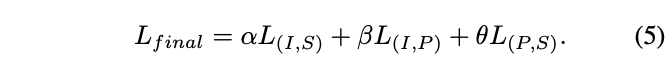
在ULIP的默认设置中,α被设置为0, β和θ被设置为1,每两个模态之间的对比学习损失函数的定义如下,这里M1和M2指三个模态中的任意两个模态:
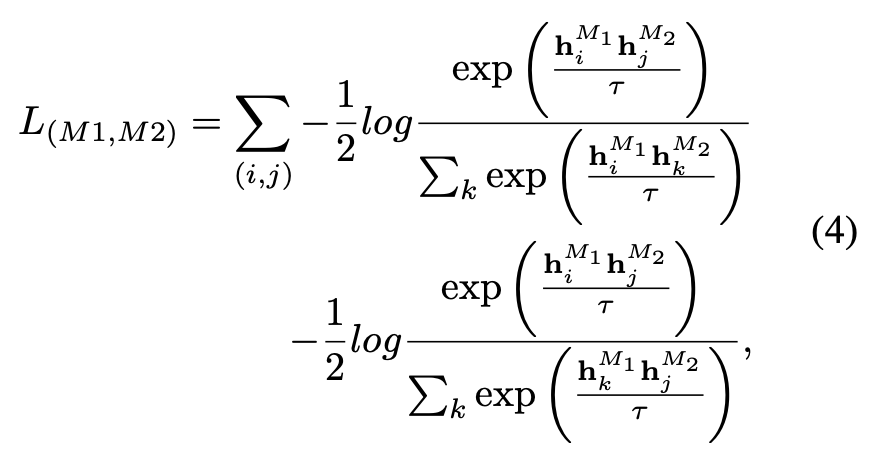
ULIP还做了由图像到3D的retrieval的实验,效果如下:
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。
 106
查看详情
106
查看详情


实验结果可以看出ULIP预训练的模型已经能够学习到图像和三维点云间有意义的多模态特征。
令人惊讶的是,相较于其他的检索到的三维模型,第一名检索到的三维模型与查询图像的外观最为接近。
例如,当我们使用来自不同飞机类型(战斗机和客机)的图片进行检索(第二行和第三行),检索到的最接近的3D点云仍然保留了查询图像的微妙差异。
这里是一个3D物体生成多角度文字描述的示例。我们先将3D物体以一组视角渲染成2D图像,接着使用大型多模态模型为所生成的所有图像生成描述
ULIP-2在ULIP的基础上,利用大型多模态模型为3D物体生*方面对应的语言描述,从而收集可扩展的多模态预训练数据,无需任何人工标注,使预训练过程和训练后的模型更加高效并且增强其适应性。
ULIP-2的方法包括为每个3D物体生成多角度不同的语言描述,然后用这些描述来训练模型,使3D物体、2D图像、和语言描述在特征空间对齐一致。
这个框架使得无需手动注释就可以创建大量的三模态数据集,从而充分发挥多模态预训练的潜力。
ULIP-2还发布了生成的大规模三模态数据集:「ULIP - Obj*erse Triplets」和「ULIP - ShapeNet Triplets」。

两个tri-modal的datasets的一些统计数据
ULIP系列在多模态下游任务和3D表达的微调实验中均取得了惊人的效果,尤其ULIP-2中的预训练是完全不需要借助任何人工的标注就可以实现的。
ULIP-2在ModelNet40的下游零样本分类任务中取得了显著的提升(74.0%的top-1准确率);在真实世界的ScanObjectNN基准测试中,它仅用1.4M参数就取得了91.5%的总体准确率,这标志着在无需人工3D标注的情况下,实现了可扩展的多模态3D表示学习的突破。
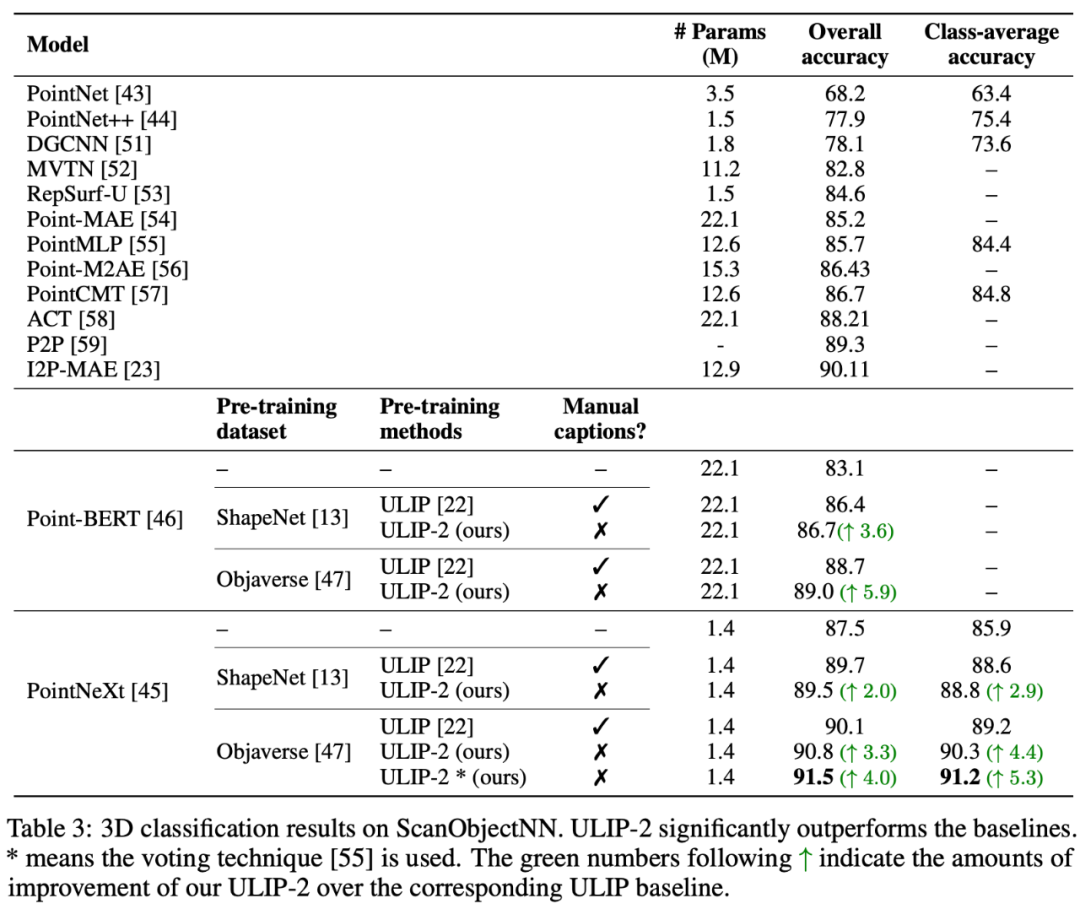
两篇论文均做了详尽的消融实验。
在「ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding」中,由于ULIP的预训练框架有三个模态的参与,所以作者用实验探究了究竟是只对齐其中的两个模态好还是对齐所有三个模态好,实验结果如下:
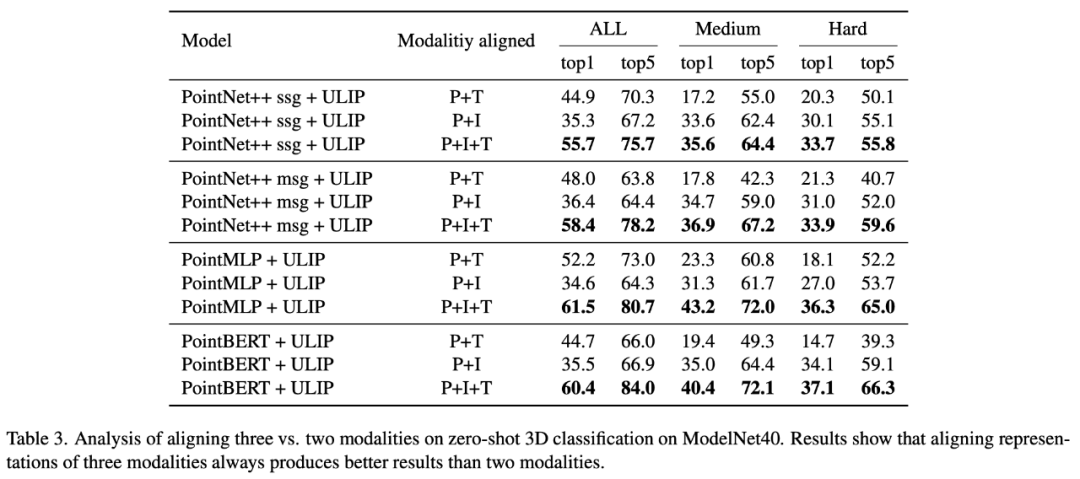
从实验结果中可以看到,在不同的3D backbone中,对齐三个模态一致的比只对齐两个模态好,这也应证了ULIP的预训练框架的合理性。
在「ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding」中,作者探究了不同的大型多模态模型会对预训练的框架有什么影响,结果如下:
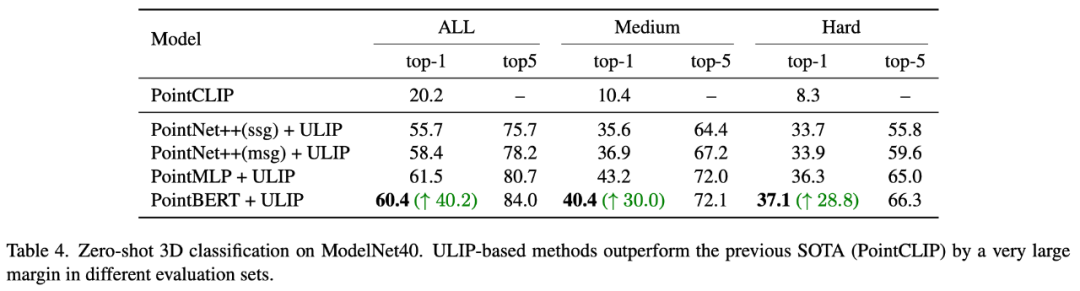
实验结果可以看出,ULIP-2框架预训练的效果可以随着使用的大型多模态模型的升级而提升,具有一定的成长性。
在ULIP-2中,作者还探索了在生成tri-modal的数据集是采用不同数量的视角会如何影响整体预训练的表现,实验结果如下:
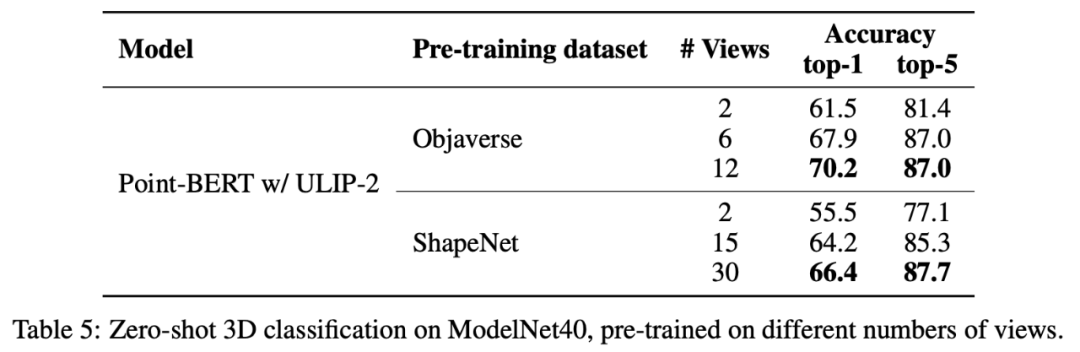
实验结果显示,随着使用的视角数量的增加,预训练的模型的zero-shot classification的效果也会随之增加。
这也应证了ULIP-2中的观点,更全方位多样性的语言描述会对多模态预训练有正向的作用。
除此之外,ULIP-2还探究了取CLIP排序过的不同topk的语言描述会对多模态预训练有什么影响,实验结果如下:
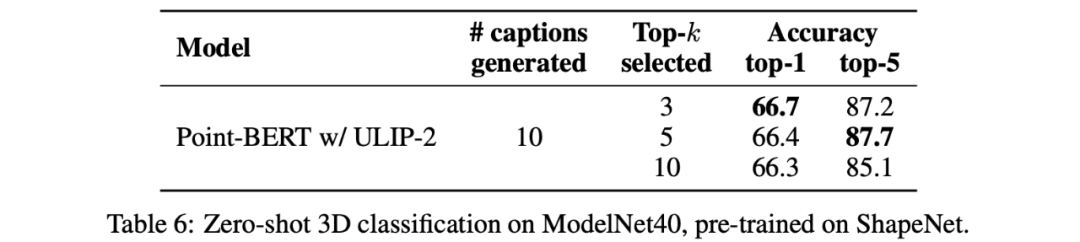
实验结果表明:ULIP-2的框架对不同的topk有一定的鲁棒性,论文中采用了top 5作为默认设置。
由Salesforce AI,斯坦福大学,得克萨斯大学奥斯汀分校联手发布的ULIP项目(CVPR2025)和ULIP-2正在改变3D理解领域。
ULIP将不同的模态对齐到一个统一的空间,增强了3D特征的学习并启用了跨模态应用。
ULIP-2进一步发展,为3D对象生成整体语言描述,创建并开源了大量的三模态数据集,并且这个过程无需人工标注。
这些项目在3D理解方面设定了新的基准,为机器真正理解我们三维世界的未来铺平了道路。
Salesforce AI:
Le Xue (薛乐), Mingfei Gao (高明菲),Chen Xing(星辰),Ning Yu(于宁), Shu Zhang(张澍),Junnan Li(李俊男), Caiming Xiong(熊蔡明),Ran Xu(徐然),Juan carlos niebles, Silvio s*arese。
斯坦福大学:
Prof. Silvio S*arese, Prof. Juan Carlos Niebles, Prof. Jiajun Wu(吴佳俊)。
UT Austin:
Prof. Roberto Martín-Martín。
以上就是无需标注数据,「3D理解」进入多模态预训练时代!ULIP系列全面开源,刷新SOTA的详细内容,更多请关注其它相关文章!
# 有什么
# 句容seo快排
# 营销推广方式就择火1星
# 做推广的网站的公司
# 精准获客营销推广
# 线上农产品网站推广方案
# 黑帽seo学习论坛
# 一个营销号推广赚钱吗
# 网站优化软件推荐电脑
# 昌黎环保网站建设配置
# 兰州网站推广团队有哪些
# 3D
# 前十
# 会对
# 采用了
# 斯坦福大学
# 得克萨斯
# 奥斯汀
# 模态
# 开源
# 多模
# 机器
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
抛媚眼给瞎子看?微软、谷歌的AI广告被广告主抵制
Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
Moka发布AI原生HR SaaS产品“Moka Eva”,布局AGI时代
AI 冥想应用 Ogimi.ai 推出,可为用户提供教练级个性化指导
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
焊接协作机器人或将成为26届埃森展最大看点
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
DragGAN开源三天Star量23k,这又来一个DragDiffusion
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
两型无人机完成交付!国家级机动观测业务正式启动
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
联想首发AI PC于今年秋季,英特尔CEO确认AI PC时代来临
李开复官宣新公司「零一万物」,进军 AI 2.0
优傲机器人的人机协作技术 助力中小企发展
即时 AI再次升级 30秒生成自带动效的网页 生成速度提升100%
【机智云物联网低功耗转接板】远程环境数据采集探索
中兴通讯无人机高空基站助力北京门头沟受灾乡镇保障应急通信
云深处科技绝影 Lite3 与 X20 四足机器人亮相
中美陷入囚徒困境,人工智能变得不可控?可参考核不扩散条约规范
陈丹琦ACL学术报告来了!详解大模型「*」数据库7大方向3大挑战,3小时干货满满
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
全场景智能车:智能无处不在|芯驰亮相世界人工智能大会
借力AI!PCB全球巨头,有爆发潜质吗?
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
VR健身应用《FitXR》将取消Quest 1端会员服务
腾讯机器狗进化:通过深度学习掌握自主决策能力
世界人工智能大会中西部县域数字就业中心组团亮相
工信部信通院发布《2025大模型和AIGC产业图谱》 360智脑覆盖全产业链
美图秀秀发布7款AI产品:支持用户创作、商业创作
五项人工智能尚未能够实现的任务
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
Meta Quest订阅服务每月7.99美元畅玩两款VR游戏应用
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
鸿蒙4即将支持大规模AI模型
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
当孔子遇见AI|尼山的“数字”
2025WRC世界机器人大赛锦标赛(烟台)收官!斯坦星球勇夺VEX赛项冠亚军!
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
官宣!爱康AI未来之夜三大亮点提前剧透!
学生作文评分的新趋势:教师与AI的合作模式
华为即将推出HarmonyOS 4,再度领先行业的AI技术
最大助力35公斤 外骨骼机器人或在养老、医疗领域“大展身手”
人工智能和你聊天 成本有多高
元宇宙技术带你穿梭“大运河”,江苏书展上的数字阅读馆吸睛小读者
2023-06-20

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
