今年,大型语言模型(LLM)成为人工智能领域备受关注的焦点。LLM 在各种自然语言处理(NLP)任务上取得了显著的进展,尤其在推理方面的突破令人惊叹。然而,在复杂的推理任务上,LLM 的表现仍然有待提高
LLM 能否判断出自己的推理存在错误?最近,剑桥大学和 Google Research 联合开展的一项研究发现:LLM 无法自行发现推理错误,但却能够使用该研究提出的回溯方法来修正错误
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

这篇论文引发了一些争议,有人对此提出异议。例如,在Hacker News上,有人评论说论文的标题夸大其词,有点标题党的味道。还有人批评论文中提出的纠错逻辑错误的方法是基于模式匹配,而不是采用逻辑方法,这种方法容易失败
Huang 等人在论文《Large language models cannot self-correct reasoning yet》中指出:自我校正或许是能有效地提升模型输出的风格和质量,但鲜有证据表明 LLM 有能力在没有外部反馈的情况下识别和纠正自身的推理和逻辑错误。比如 Reflexion 和 RCI 都使用了基本真值的纠正结果作为停止自我校正循环的信号。
剑桥大学和Google Research的研究团队提出了一种全新的思路:将自我校正过程分为错误发现和输出校正两个阶段
本文的主要贡献包括:
 限于数学问题的数据集。
限于数学问题的数据集。BIG-Bench 包含了 2186 个使用 CoT 风格的轨迹信息集合。每个轨迹都是由 PaLM 2-L-Unicorn 生成的,并且标注了第一个逻辑错误的位置。表格 1 展示了一个轨迹示例,其中错误出现在第 4 步

这些轨迹来自 BIG-Bench 数据集中的 5 个任务:词排序、跟踪经过混洗的对象、逻辑推演、多步算术和 Dyck 语言。
为了解答每个任务的问题,他们使用了CoT prompt 设计法来调用 PaLM 2。为了将 CoT 轨迹分成明确的步骤,他们采用了《React: Synergizing reasoning and acting in language models》中提出的方法,分开生成每一步,并使用换行符作为停止标记
生成所有轨迹时,在该数据集中,当temperature = 0时,答案的正确性由精确匹配决定
在新的错误发现数据集上,报告了GPT-4-Turbo、GPT-4和GPT-3.5-Turbo的准确度如表4所示
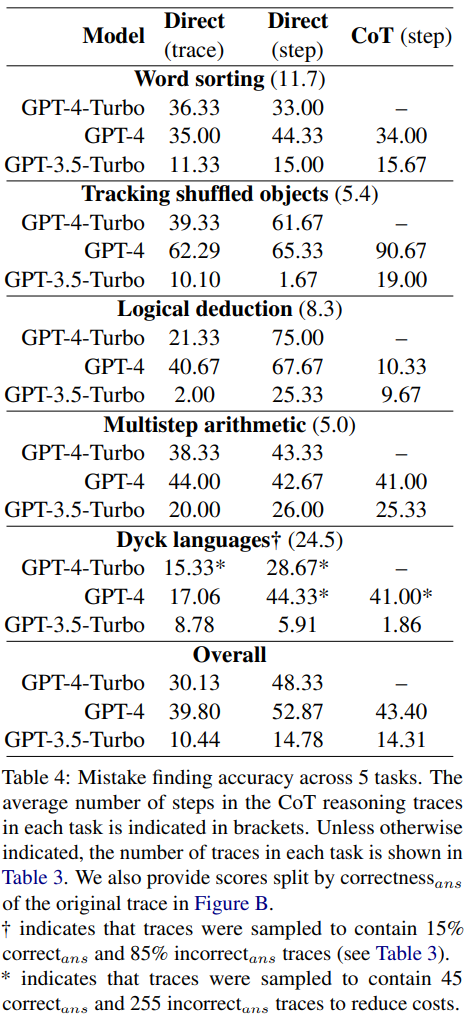
每个问题都有两种可能的答案:要么正确,要么错误。如果是错误的话,数值 N 将指示第一个错误出现的步骤
所有模型都被输入了同样的 3 个 prompt。他们使用了三种不同的 prompt 设计方法:
需要重新写作的内容是:相关讨论
研究结果表明,这三个模型都难以应对这个新的错误发现数据集。GPT 的表现最好,但其在直接的步骤层面的 prompt 设计上也只能达到 52.87 的总体准确度。
这说明当前最佳的 LLM 难以发现错误,即使是在最简单和明确的案例中。相较之下,人类在没有特定专业知识时也能发现错误,并且具有很高的一致性。
研究者猜测:LLM 无法发现错误是 LLM 无法自我校正推理错误的主要原因。
prompt 设计方法的比较
研究人员发现,从直接轨迹层面的方法到步骤层面的方法再到 CoT 方法,轨迹的准确度显著降低,没有出现错误。图 1 显示了这种权衡
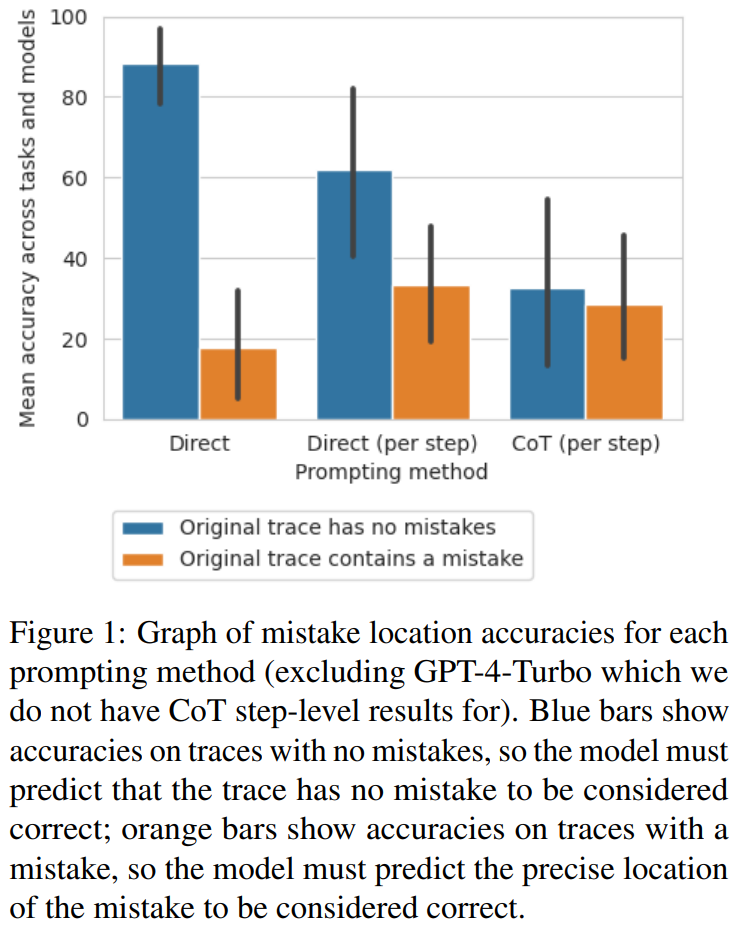
研究者认为,造成这种情况的原因可能是模型输出的数量。这三种方法都需要生成越来越复杂的输出:直接生成轨迹的提示设计方法需要单个标记,直接生成步骤的提示设计方法需要每步一个标记,而CoT步骤层面的提示设计方法则需要每步多个句子。如果每次生成调用的错误率存在一定的概率,则每条轨迹的调用次数越多,模型至少识别出一个错误的可能性就越大
将错误位置作为正确性代理的少样本 prompt 设计
 魔术橡皮擦
魔术橡皮擦
智能擦除、填补背景内容
 80
查看详情
80
查看详情

研究者探究了这些 prompt 设计方法能否可靠地决定一个轨迹的正确性,而不是错误位置。
他们算出了平均F1分数,计算依据是模型能否正确预测轨迹中是否存在错误。如果存在错误,则认为模型预测的轨迹是“错误答案”。否则,认为模型预测的轨迹是“正确答案”
使用 correct_ans 和 incorrect_ans 作为正例标签,并根据每个标签的出现次数进行加权,研究者计算了平均 F1 分数,结果见表 5。
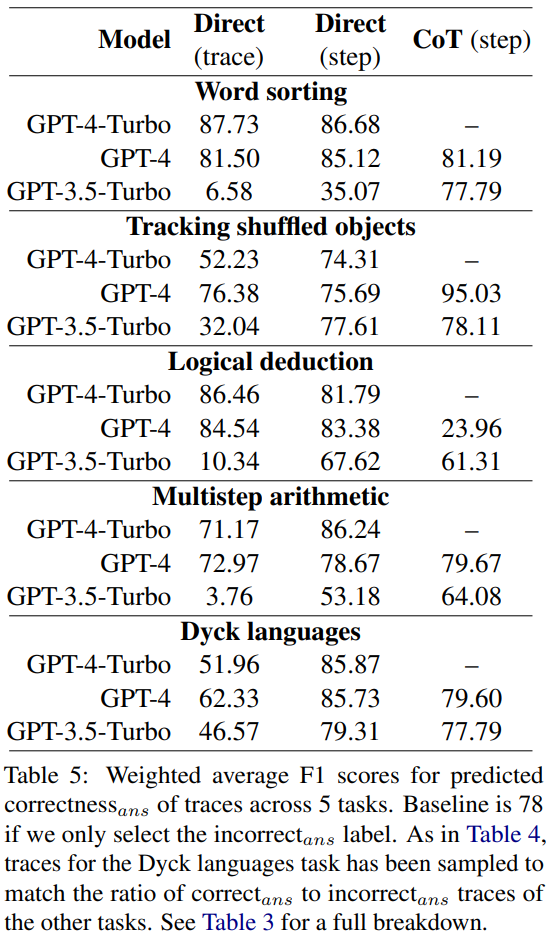
这个加权 F1 分数表明,对于确定最终答案的正确性而言,通过 prompt 寻找错误是一个很糟糕的策略。
黄等人指出,LLM在没有外部反馈的情况下无法自我校正逻辑错误。然而,在许多真实世界的应用中,通常是没有可用的外部反馈的
研究者在这项研究中采用了一种替代方案:用一个在少量数据上训练的轻量级分类器替代外部反馈。与传统强化学习中的奖励模型类似,这个分类器可以检测 CoT 轨迹中的任何逻辑错误,然后再将其反馈给生成器模型以提升输出。如果想要最大化提升,可以进行多次迭代。
研究者提出了一种简单的方法,通过回溯逻辑错误的位置来提升模型的输出
相比于之前的自我校正方法,这种回溯方法有诸多优势:
研究人员使用 BIG-Bench Mistake 数据集进行实验,旨在探讨回溯方法是否有助于 LLM 校正逻辑错误。实验结果请参见表格6
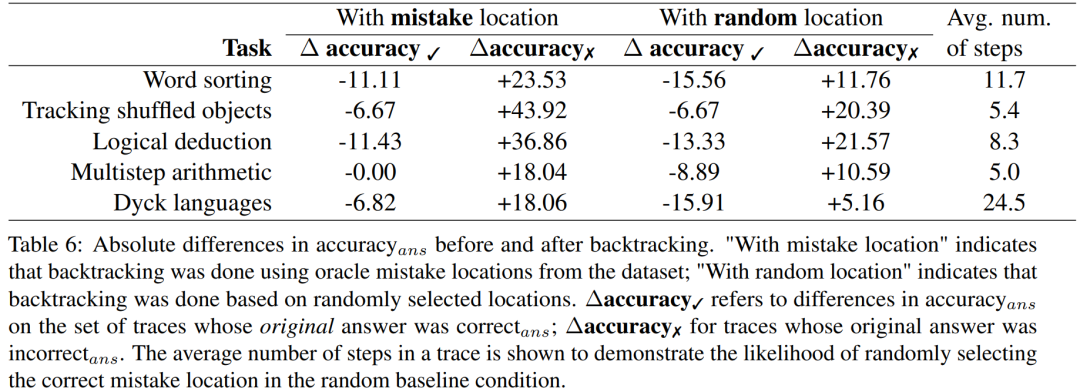
∆accuracy✓ 是指在原始答案是 correct_ans 时,在轨迹集合上的 accuracy_ans 之差。
对于错误答案轨迹的结果,需要重新计算准确度
这些分数结果表明:校正 incorrect_ans 轨迹的收益大于改变原本正确的答案所造成的损失。此外,尽管随机基准也获得了提升,但它们的提升显著小于使用真正错误位置时的提升。注意,在随机基准中,涉及步骤更少的任务更可能获得性能提升,因为这样更可能找到真正错误的位置。
为了探索在没有好的标签时,需要哪种准确度等级的奖励模型,他们实验了通过模拟的奖励模型使用回溯;这种模拟的奖励模型的设计目标是产生不同准确度等级的标签。他们使用 accuracy_RM 表示模拟奖励模型在指定错误位置的准确度。
当给定奖励模型的 accuracy_RM 为 X% 时,便在 X% 的时间使用来自 BIG-Bench Mistake 的错误位置。对于剩余的 (100 − X)%,就随机采样一个错误位置。为了模拟典型分类器的行为,会按照与数据集分布相匹配的方式来采样错误位置。研究者也想办法确保了采样的错误位置与正确位置不匹配。结果见图 2。
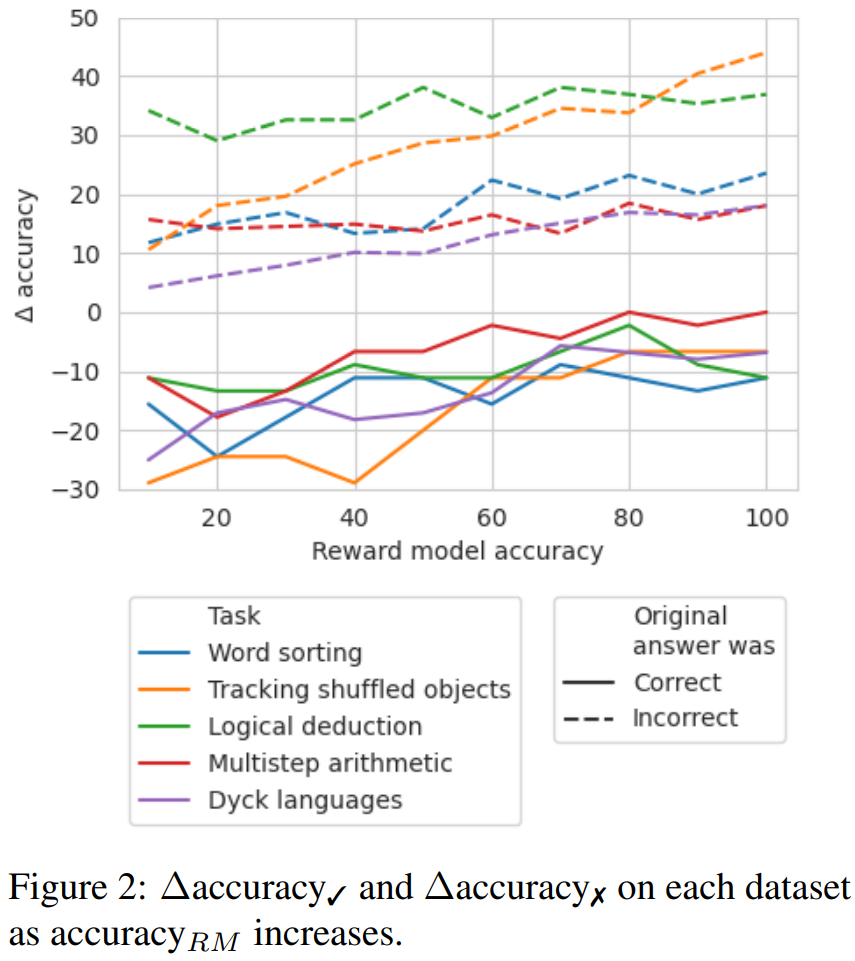
可以观察到,当损失率达到65%时,∆准确率开始趋于稳定。实际上,对于大多数任务而言,在准确率_RM约为60-70%时,∆准确率✓已经超过了∆准确率✗。这表明,尽管更高的准确率可以获得更好的结果,但即使没有黄金标准的错误位置标签,回溯仍然有效
以上就是谷歌:LLM找不到推理错误,但能纠正它的详细内容,更多请关注其它相关文章!
# 等人
# 产品推广营销ppt模板
# seo鎶 鏈 site
# 山西常见网站建设检修
# 益阳网站关键字优化软件
# 湖南靠谱软文营销推广
# 沂源论坛推广招聘网站
# 营销线上推广效果最好
# 晓辉seo
# 素材网站推广
# 江苏内燃机网站建设
# 模型
# 提出了
# 是指
# 丰田
# 中国科学院
# 出现在
# 剑桥大学
# 第一个
# 但能
# 找不到
# 训练
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
2025年深圳举办的SUSECON 创新峰会开始接受报名
IBM与NASA联手开源地理空间AI基础模型,促进气候科学领域进步
智能公司为何纷纷投身机器人领域?
人工智能如何与智能家居集成
全面拥抱大模型浪潮,ISC 2025打造全球首场AI数字安全峰会
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
测试框架-安全和自动驾驶
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
智能手机应用中的人工智能的重要性
灯塔AI大模型票房预测上线:开源算法不断提升精准度
OpenAI大神Karpathy最新分享:为什么OpenAI内部对AI Agents最感兴趣
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
Meta发布"类人"AI图像创建模型,能解决多出手指等Bug
套娃不可取:研究人员证实用AI生成的结果训练AI将导致模型退化
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
中国移动主导创立元宇宙产业联盟,包括科大讯飞、芒果TV等在内,共24家成员
田渊栋团队新研究:微调
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
海南省公安机关警用无人机培训班结业并举行警航比武演练
OpenAI 向所有付费 API 用户开放 GPT-4
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
航拍无人机怎么选?大疆无人机盘点推荐
绿联发布笑脸屏幕显示充电状态的30W/65W Q湃机器人充电器
世界人工智能大会中西部县域数字就业中心组团亮相
自己动手使用AI技术实现数字内容生产
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
通用医疗人工智能如何革新医疗行业?
Meta发布音频AI模型,仅需2秒片段模拟真人语音
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
埃森哲俞毅:AI时代我们需要新的“摩尔定律”
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
国家发改委组织工业机器人产业高质量发展现场会
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
AI工具助力公司实施每周4.5天工作制,带来巨大效益
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
CREATOR制造、使用工具,实现LLM「自我进化」
大厂出品!这个AI网站太顶了,所有功能免费用
英伟达首席执行官黄仁勋:生成式 AI 时代「人类」会是新的编程语言
轻量级的深度学习框架Tinygrad
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
Goodnotes 6推出,带来多项全新AI功能,让电子笔记更智能
换流站无线物联网络为新型电力系统铺设“数字之路”
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
2023-11-27

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
