自监督学习(SSL)在最近几年取得了很大的进展,在许多下游任务上几乎已经达到监督学习方法的水平。但是,由于模型的复杂性以及缺乏有标注训练数据集,我们还一直难以理解学习到的表征及其底层的工作机制。此外,自监督学习中使用的 pretext 任务通常与特定下游任务的直接关系不大,这就进一步增大了解释所学习到的表征的复杂性。而在监督式分类中,所学到的表征的结构往往很简单。
相比于传统的分类任务(目标是准确将样本归入特定类别),现代 SSL 算法的目标通常是最小化包含两大成分的损失函数:一是对增强过的样本进行聚类(不变性约束),二是防止表征坍缩(正则化约束)。举个例子,对于同一样本经过不同增强之后的数据,对比式学习方法的目标是让这些样本的分类结果一样,同时又要能区分经过增强之后的不同样本。另一方面,非对比式方法要使用正则化器(regularizer)来避免表征坍缩。
自监督学习可以利用辅助任务(pretext)无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。近日,图灵奖得主 Yann LeCun 在内的多位研究者发布了一项研究,宣称对自监督学习进行了逆向工程,让我们得以了解其训练过程的内部行为。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/abs/2305.15614v2
这篇论文通过一系列精心设计的实验对使用 SLL 的表征学习进行了深度分析,帮助人们理解训练期间的聚类过程。具体来说,研究揭示出增强过的样本会表现出高度聚类的行为,这会围绕共享同一图像的增强样本的含义嵌入形成质心。更出人意料的是,研究者观察到:即便缺乏有关目标任务的明确信息,样本也会根据语义标 签发生聚类。这表明 SSL 有能力根据语义相似性对样本进行分组。
签发生聚类。这表明 SSL 有能力根据语义相似性对样本进行分组。
由于自监督学习(SSL)通常用于预训练,让模型做好准备适应下游任务,这带来了一个关键问题:SSL 训练会对所学到的表征产生什么影响?具体来说,训练期间 SSL 的底层工作机制是怎样的,这些表征函数能学到什么类别?
为了调查这些问题,研究者在多种设置上训练了 SSL 网络并使用不同的技术分析了它们的行为。
数据和增强:本文提到的所有实验都使用了 CIFAR100 图像分类数据集。为了训练模型,研究者使用了 SimCLR 中提出的图像增强协议。每一个 SSL 训练 session 都执行 1000 epoch,使用了带动量的 SGD 优化器。
骨干架构:所有的实验都使用了 RES-L-H 架构作为骨干,再加上了两层多层感知器(MLP)投射头。
线性探测(linear probing):为了评估从表征函数中提取给定离散函数(例如类别)的有效性,这里使用的方法是线性探测。这需要基于该表征训练一个线性分类器(也称为线性探针),这需要用到一些训练样本。
样本层面的分类:为了评估样本层面的可分离性,研究者创建了一个专门的新数据集。
其中训练数据集包含来自 CIFAR-100 训练集的 500 张随机图像。每张图像都代表一个特定类别并会进行 100 种不同的增强。因此,训练数据集包含 500 个类别的共计 50000 个样本。测试集依然是用这 500 张图像,但要使用 20 种不同的增强,这些增强都来自同一分布。因此,测试集中的结果由 10000 个样本构成。为了在样本层面衡量给定表征函数的线性或 NCC(nearest class-center / 最近类别中心)准确度,这里采用的方法是先使用训练数据计算出一个相关的分类器,然后再在相应测试集上评估其准确率。
在帮助分析深度学习模型方面,聚类过程一直以来都发挥着重要作用。为了直观地理解 SSL 训练,图 1 通过 UMAP 可视化展示了网络的训练样本的嵌入空间,其中包含训练前后的情况并分了不同层级。
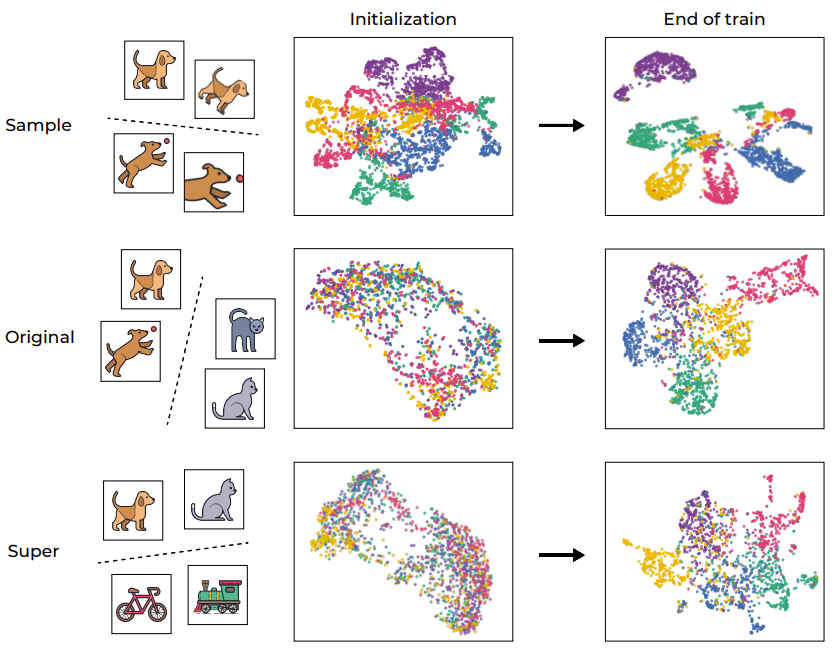
图 1:SSL 训练引起的语义聚类
正如预期的那样,训练过程成功地在样本层面上对样本进行了聚类,映射了同一图像的不同增强(如第一行图示)。考虑到目标函数本身就会鼓励这种行为(通过不变性损失项),因此这样的结果倒是不意外。然而,更值得注意的是,该训练过程还会根据标准 CIFAR-100 数据集的原始「语义类别」进行聚类,即便该训练过程期间缺乏标签。有趣的是,更高的层级(超类别)也能被有效聚类。这个例子表明,尽管训练流程直接鼓励的是样本层面的聚类,但 SSL 训练的数据表征还会在不同层面上根据语义类别来进行聚类。
为了进一步量化这个聚类过程,研究者使用 VICReg 训练了一个 RES-10-250。研究者衡量的是 NCC 训练准确度,既有样本层面的,也有基于原始类别的。值得注意的是,SSL 训练的表征在样本层面上展现出了神经坍缩(neural collapse,即 NCC 训练准确度接近于 1.0),然而在语义类别方面的聚类也很显著(在原始目标上约为 0.41)。
如图 2 左图所示,涉及增强(网络直接基于其训练的)的聚类过程大部分都发生在训练过程初期,然后陷入停滞;而在语义类别方面的聚类(训练目标中并未指定)则会在训练过程中持续提升。
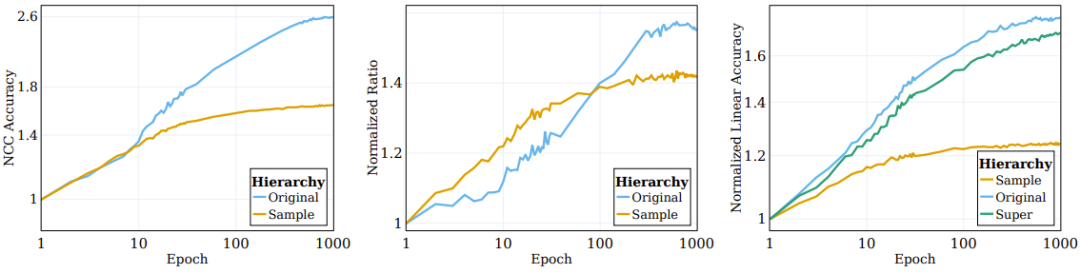
图 2:SSL 算法根据语义目标对对数据的聚类
之前有研究者观察到,监督式训练样本的顶层嵌入会逐渐向一个类质心的结构收敛。为了更好地理解 SSL 训练的表征函数的聚类性质,研究者调查了 SSL 过程中的类似情况。其 NCC 分类器是一种线性分类器,其表现不会超过最佳的线性分类器。通过评估 NCC 分类器与同样数据上训练的线性分类器的准确度之比,能够在不同粒度层级上研究数据聚类。图 2 的中图给出了样本层面类别和原始目标类别上的这一比值的变化情况,其值根据初始化的值进行了归一化。随着 SSL 训练的进行,NCC 准确度和线性准确度之间的差距会变小,这说明增强后的样本会根据其样本身份和语义属性逐渐提升聚类水平。
此外,该图还说明,样本层面的比值起初会高一些,这说明增强后的样本会根据它们的身份进行聚类,直到收敛至质心(NCC 准确度和线性准确度的比值在 100 epoch 时 ≥ 0.9)。但是,随着训练继续,样本层面的比值会饱和,而类别层面的比值会继续增长并收敛至 0.75 左右。这说明增强后的样本首先会根据样本身份进行聚类,实现之后,再根据高层面的语义类别进行聚类。
SSL 训练中隐含的信息压缩
如果能有效进行压缩,那么就能得到有益又有用的表征。但 SSL 训练过程中是否会出现那样的压缩却仍是少有人研究的课题。
为了了解这一点,研究者使用了互信息神经估计(Mutual Information Neural Estimation/MINE),这种方法可以估计训练过程中输入与其对应嵌入表征之间的互信息。这个度量可用于有效衡量表征的复杂度水平,其做法是展现其编码的信息量(比特数量)。
图 3 的中图报告了在 5 个不同的 MINE 初始化种子上计算得到的平均互信息。如图所示,训练过程会有显著的压缩,最终形成高度紧凑的训练表征。
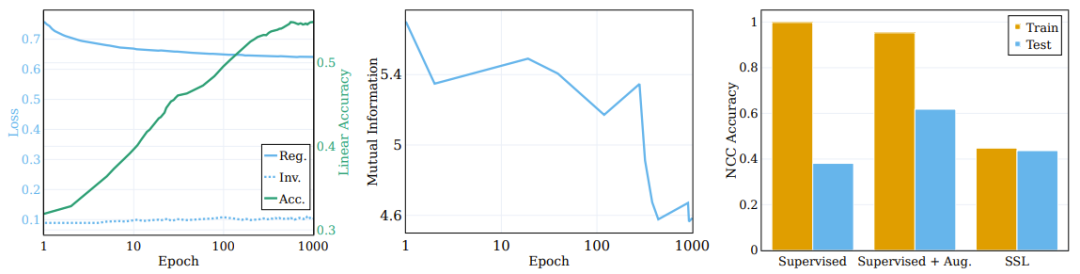
左侧图表显示了 ssl 训练模型在训练过程中正则化和不变性损失的变化以及原始目标线性测试准确度。(中)训练期间输入和表征之间的互信息的压缩。(右)ssl 训练学习聚类的表征。
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。
 106
查看详情
106
查看详情

正则化损失的作用
目标函数包含两项:不变性和正则化。不变性项的主要功能是强化同一样本的不同增强的表征之间的相似性。而正则化项的目标是帮助防止表征坍缩。
为了探究这些分量对聚类过程的作用,研究者将目标函数分解为了不变性项和正则化项,并观察它们在训练过程中的行为。比较结果见图 3 左图,其中给出了原始语义目标上的损失项的演变以及线性测试准确度。不同于普遍流行的想法,不变性损失项在训练过程中并不会显著改善。相反,损失(以及下游的语义准确度)的改善是通过降低正则化损失实现的。
由此可以得出结论:SSL 的大部分训练过程都是为了提升语义准确度和所学表征的聚类,而非样本层面的分类准确度和聚类。
从本质上讲,这里的发现表明:尽管自监督学习的直接目标是样本层面的分类,但其实大部分训练时间都用于不同层级上基于语义类别的数据聚类。这一观察结果表明 SSL 方法有能力通过聚类生成有语义含义的表征,这也让我们得以了解其底层机制。
监督学习和 SSL 聚类的比较
深度网络分类器往往是基于训练样本的类别将它们聚类到各个质心。但学习得到的函数要能真正聚类,必须要求这一性质对测试样本依然有效;这是我们期望得到的效果,但效果会差一点。
这里有一个有趣的问题:相比于监督学习的聚类,SSL 能在多大程度上根据样本的语义类别来执行聚类?图 3 右图报告了在不同场景(使用和不使用增强的监督学习以及 SSL)的训练结束时的 NCC 训练和测试准确度比率。
尽管监督式分类器的 NCC 训练准确度为 1.0,显著高于 SSL 训练的模型的 NCC 训练准确度,但 SSL 模型的 NCC 测试准确度却略高于监督式模型的 NCC 测试准确度。这说明两种模型根据语义类别的聚类行为具有相似的程度。有意思的是,使用增强样本训练监督式模型会稍微降低 NCC 训练准确度,却会大幅提升 NCC 测试准确度。
语义类别是根据输入的内在模式来定义输入和目标的关系。另一方面,如果将输入映射到随机目标,则会看到缺乏可辨别的模式,这会导致输入和目标之间的连接看起来很任意。
研究者还探究了随机性对模型学习所需目标的熟练程度的影响。为此,他们构建了一系列具有不同随机度的目标系统,然后检查了随机度对所学表征的影响。他们在用于分类的同一数据集上训练了一个神经网络分类器,然后使用其不同 epoch 的目标预测作为具有不同随机度的目标。在 epoch 0 时,网络是完全随机的,会得到确定的但看似任意的标签。随着训练进行,其函数的随机性下降,最终得到与基本真值目标对齐的目标(可认为是完全不随机)。这里将随机度归一化到 0(完全不随机,训练结束时)到 1(完全随机,初始化时)之间。
图 4 左图展示了不同随机度目标的线性测试准确度。每条线都对应于不同随机度的 SSL 不同训练阶段的准确度。可以看到,在训练过程中,模型会更高效地捕获与「语义」目标(更低随机度)更接近的类别,同时在高随机度的目标上没有表现出显著的性能改进。
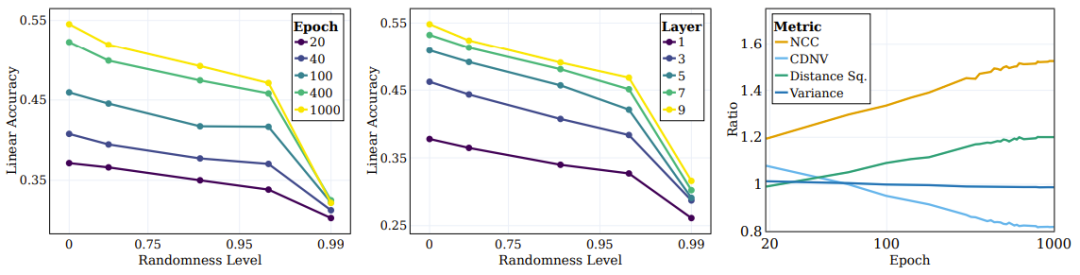
图 4:SSL 持续学习语义目标,而非随机目标
深度学习的一个关键问题是理解中间层对分类不同类型类别的作用和影响。比如,不同的层会学到不同类型的类别吗?研究者也探索了这个问题,其做法是在训练结束时不同目标随机度下评估不同层表征的线性测试准确度。如图 4 中图所示,随着随机度下降,线性测试准确度持续提升,更深度的层在所有类别类型上都表现更优,而对于接近语义类别的分类,性能差距会更大。
研究者还使用了其它一些度量来评估聚类的质量:NCC 准确度、CDNV、平均每类方差、类别均值之间的平均平方距离。为了衡量表征随训练进行的改进情况,研究者为语义目标和随机目标计算了这些指标的比率。图 4 右图展示了这些比率,结果表明相比于随机目标,表征会更加偏向根据语义目标来聚类数据。有趣的是,可以看到 CDNV(方差除以平方距离)会降低,其原因仅仅是平方距离的下降。方差比率在训练期间相当稳定。这会鼓励聚类之间的间距拉大,这一现象已被证明能带来性能提升。
之前的研究已经证明,在监督学习中,中间层会逐渐捕获不同抽象层级的特征。初始的层倾向于低层级的特征,而更深的层会捕获更抽象的特征。接下来,研究者探究了 SSL 网络能否学习更高层面的层次属性以及哪些层面与这些属性的关联性更好。
在实验中,他们计算了三个层级的线性测试准确度:样本层级、原始的 100 个类别、20 个超类别。图 2 右图给出了为这三个不同类别集计算的数量。可以观察到,在训练过程中,相较于样本层级的类别,在原始类别和超类别层级上的表现的提升更显著。
接下来是 SSL 训练的模型的中间层的行为以及它们捕获不同层级的目标的能力。图 5 左和中图给出了不同训练阶段在所有中间层上的线性测试准确度,这里度量了原始目标和超目标。图 5 右图给出超类别和原始类别之间的比率。
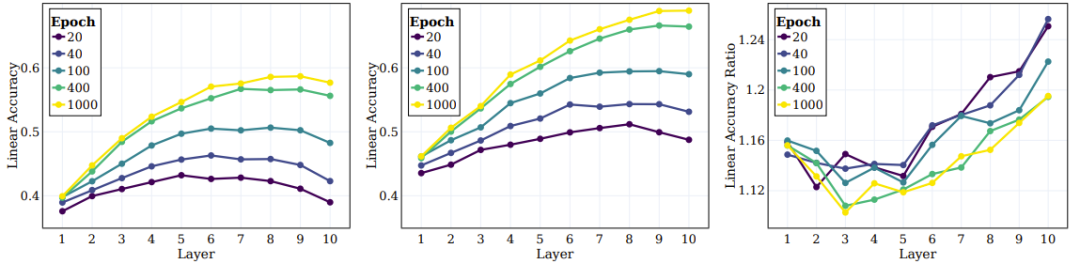
图 5:SSL 能在整体中间层中有效学习语义类别
研究者基于这些结果得到了几个结论。首先,可以观察到随着层的深入,聚类效果会持续提升。此外,与监督学习情况类似,研究者发现在 SSL 训练期间,网络每一层的线性准确度都有提升。值得注意的是,他们发现对于原始类别,最终层并不是最佳层。近期的一些 SSL 研究表明:下游任务能高度影响不同算法的性能。本文的研究拓展了这一观察结果,并且表明网络的不同部分可能适合不同的下游任务与任务层级。根据图 5 右图,可以看出,在网络的更深层,超类别的准确度的提升幅度超过原始类别。
以上就是Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的的详细内容,更多请关注其它相关文章!
# 中图
# 优化网站有哪些渠道
# 营销攻关推广
# 江苏网站排名优化
# 合肥网站的优化
# 医院网站整体优化建议
# 安徽多语言网站推广方案
# 武汉外贸网站优化
# 什么是网站建设价格
# 设计网站竞价推广工作室
# 济宁网站优化预算哪家好
# 研究
# 右图
# 不变性
# 使用了
# 中间层
# 出了
# 这一
# 过程中
# 是这样
# 的是
# 监督
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
抖音在Android平台获得VR|直播|软件著作权
世界水下机器人大赛:9国青年携手逐梦深蓝
美图公司影像节或发布AI设计新品
两型无人机完成交付!国家级机动观测业务正式启动
人工智能自己玩自己
杭州举办第19届亚运会,主题为「亚运元宇宙」的发布仪式举行
华为余承东表示:鸿蒙可能拥有强大的人工智能大模型能力
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
OpenAI高管:AI能创造新的就业机会 但也会淘汰一些
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
自动驾驶汽车避障、路径规划和控制技术详解
周鸿祎:用超级AI实现室温超导和核聚变,实现能源自由
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
人工智能时代的科幻译者怎么办?“做好翻译工作的高端10%”|文化观察
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
美图秀秀发布7款AI产品:支持用户创作、商业创作
选对AI智能写作软件,让创作游刃有余!
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
抢占新赛道 加快机器人产业集聚发展
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
五项人工智能尚未能够实现的任务
人工智能在交通领域的革新:智能解决方案彻底改变交通方式
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
6月14日《星空下的对话》 张朝阳陆川将畅聊人生、电影、心理学与AI
实测 AI 建筑设计软件的自动生成效果图能力
小艺将具备大模型能力,鸿蒙4加速AI普及之路
田渊栋团队新研究:微调
CharacterAI - 也许会成为会话人工智能的未来
马斯克发推讽刺人工智能,机器学习本质是统计?
大疆 Air 3 无人机售价和实物照片曝光
CREATOR制造、使用工具,实现LLM「自我进化」
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
字节、网易相继入局,AI之后大厂又找到下一个风口?
值得买科技入选“北京市通用人工智能产业创新伙伴计划”应用伙伴
改变城市交通:智慧城市中的智能交通
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
泗洪:畅通城市“血管” ,管下机器人来帮忙
调研海尔智家:AI名,家电命?
今年,全球客服中心支出将增长 16.2%,迎接对话式 AI 的浪潮,根据 Gartner 报告
上海发布大模型政策 打造AI“模”都
中国联通发布图文AI大模型,可实现以文生图、视频剪辑
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
“三夏”农忙保障用电,无人机高空巡视高压线
扎克伯格吐槽苹果Vision Pro:社交落后Meta太多,无法建设元宇宙
2023-06-15

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
