本文聚焦社交媒体虚假谣言检测,指出传统方法存在局限,深度学习是主流但实时性待提升。为此提出基于中文文本的Conv-FFD模型,以字为处理单元,通过卷积提取特征,经全连接层获检测结果。实验验证其效率,还复现了该模型及对比模型,给出数据集处理、模型构建、训练评估等过程,复现精度为0.8795,接近目标值。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

社交媒体的发展在加速信息传播的同时,也带来了虚假谣言信息的泛滥,往往会引发诸多不安定因素,并对经济和社会产生巨大的影响。
人们常说“流言止于智者”,要想不被网上的流言和谣言盅惑、伤害,首先需要对其进行科学甄别,而时下人工智能正在尝试担任这一角色。那么,在打假一线AI技术如何做到去伪存真?
传统的谣言检测模型一般根据谣言的内容、用户属性、传播方式人工地构造特征,而人工构建特征存在考虑片面、浪费人力等现象。本次实践使用基于循环神经网络(RNN)的谣言检测模型,将文本中的谣言事件向量化,通过循环神经网络的学习训练来挖掘表示文本深层的特征,避免了特征构建的问题,并能发现那些不容易被人发现的特征,从而产生更好的效果。
在现代信息物理空间中,各种社交网络服务已成为日常生活中获取信息不可或缺的一部分 。这使得社会服务用户面临着不断增长的新闻和信息量无处不在。但与此同时,各种真假新闻混杂在一起,总是让社会服务用户难以很好地辨别其本质。目前的情况无疑给网络物理社会服务的运营商带来了很大的挑战。
没有有效的技术监管手段,广大用户可能会受到威胁。一个典型案例是 2025 年早期 COVID-19 相关虚假新闻的广泛传播,带来了严重的经济和社会危害。因此,研究实用的假新闻检测方法,对于网络物理社会服务的运营商具有重要意义 。
现有的网络物理社会服务假新闻检测研究大致可分为两类:统计检索和语义计算。前者主要是对句子或段落进行分词后,搜索与异常特征相关的关键词。然后,建立一个评分模型来评估句子的真实性作为结果。然而,以这种方式拆分句子的想法很难捕捉到句子的语义特征。当没有明确的异常关键字时,很难得到理想的结果。后者更侧重于建立数学模型来以向量化形式表示句子的语义。
然后,利用机器学习中的分类或回归方法输出情感评价结果。然而,从语言学的角度来看,几乎任何一种语言都有大量的词单元,这使得向量模型的构建具有挑战性。
目前,深度学习因其先进的信息处理结构已成为语义建模的主流思想,对算法效率提出了挑战。因为在现实世界的大规模数据流中,算法的实时性对于现实实践至关重要。
现实世界的大规模数据流中,算法的实时性对于现实世界的影响巨大,为弥补之间的差距,本文以基于中文文本的谣言数据为对象,提出了一种基于深度学习的社交网络假新闻快速检测模型-Conv-FFD。Conv-FFD将中文短文本中的每个字直接作为基本处理单元。使用特征提取滤波器Conv扫描句子中的每个单元字符,通过卷积运算从一个字符和相邻字符中提取联合特征表征。最后,通过全连接层映射最终获得检测结果。
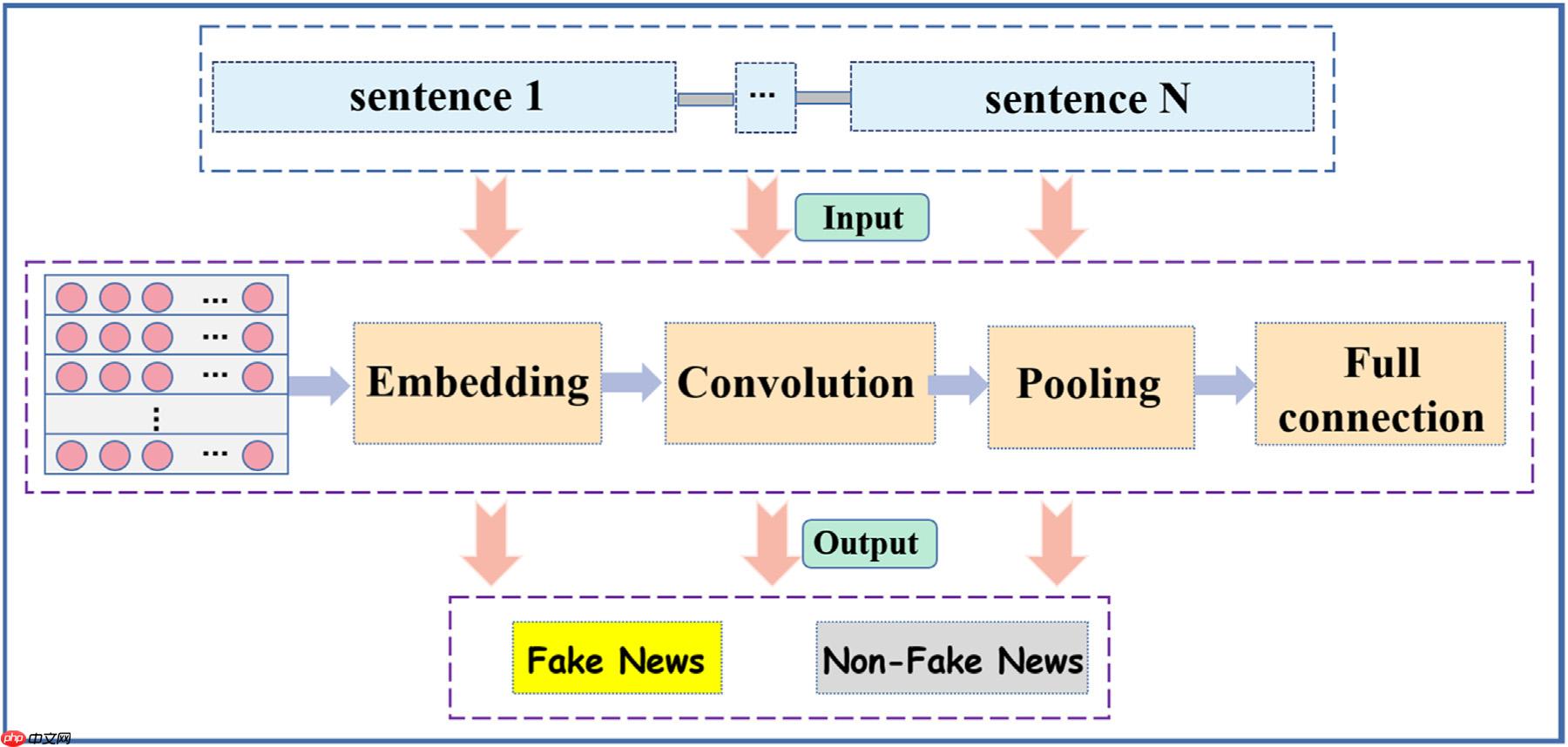
为了快速将字符级特征表示合并为句子级特征表示,选择了CNN。 CNN是一种通过卷积运算自动从目标实体中学习隐藏特征的神经网络模型。卷积算子可以看作是一个过滤器,扫描目标实体的全局特征,从而获得新的抽象特征。 CNN最常见的应用领域是计算机视觉和图像处理。由于像素级特征和词级特征都是向量的形式,因此,CNN也可以用于语义建模。
如下图所示,每个字的embedding都可以看作是一个垂直方向的向量。对于每个字符 Xn,m,假设它与其相邻的几个字符相关联。相邻字符的范围在xn,m的前d个字符和后d个字符。也就是说,xn,m−d与其相邻的2d个词组合成了一个滑动窗口。它从xn,m−d开始到字符xn,m+d结束。

实验中提出一个参数n,将所有样本分为多组,其中1个作为测试样本,剩余n个作为训练集
论文:
参考项目:
复现论文中的Conv-FFD,在Rumordataset数据集上精度为0.8795。 目标精度:0.8864 以及其中的几个对比模型。
| 模型结构 | Acc | Pre | Rec | F1 |
|---|---|---|---|---|
| Conv-FFD | 0.8795 | 0.905 | 0.8757 | 0.8901 |
| LSTM | 0.8482 | 0.8839 | 0.8365 | 0.8595 |
| Transformer | 0.8705 | 0.8859 | 0.8787 | 0.8823 |
| BiGRU | 0.8631 | 0.8747 | 0.8794 | 0.8770 |
硬件:GPU\CPU 框架: PaddlePaddle >=2.0.0
In [ ]import paddleimport paddle.nn as nnfrom paddle.nn import Conv2D, Linear, Embeddingfrom paddle import to_tensorimport paddle.nn.functional as Fprint(paddle.__version__)import os, zipfileimport io, random, jsonimport numpy as npimport matplotlib.pyplot as plt
本次实践所使用的数据是从新浪微博不实信息举报平台抓取的中文谣言数据,数据集中gong包含1538条谣言和1849条非谣言。如下图所示,每条数据均为json格式,其中text字段代表微博原文的文字内容。
更多数据集介绍请参考https://github.com/thunlp/Chinese_Rumor_Dataset。
(1)解压数据,读取并解析数据,生成all_data.txt
(2)生成数据字典,即dict.txt
(3)生成数据列表,并进行训练集与验证集的划分,train_list.txt 、eval_list.txt
(4)定义训练数据集迭代器
import os, zipfile
src_path="data/data201561/Rumor_Dataset.zip"target_path="/home/aistudio/data/Chinese_Rumor_Dataset-master"if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
In [ ]
import ioimport randomimport json#谣言数据文件路径rumor_class_dirs = os.listdir(target_path+"/Chinese_Rumor_Dataset-master/CED_Dataset/rumor-repost/")#非谣言数据文件路径non_rumor_class_dirs = os.listdir(target_path+"/Chinese_Rumor_Dataset-master/CED_Dataset/non-rumor-repost/")
original_microblog = target_path+"/Chinese_Rumor_Dataset-master/CED_Dataset/original-microblog/"#谣言标签为0,非谣言标签为1rumor_label="0"non_rumor_label="1"#分别统计谣言数据与非谣言数据的总数rumor_num = 0non_rumor_num = 0all_rumor_list = []
all_non_rumor_list = []#解析谣言数据for rumor_class_dir in rumor_class_dirs:
if(rumor_class_dir != '.DS_Store'): #遍历谣言数据,并解析
with open(original_microblog + rumor_class_dir, 'r') as f:
rumor_content = f.read()
rumor_dict = json.loads(rumor_content)
all_rumor_list.append(rumor_label+"\t"+rumor_dict["text"]+"\n")
rumor_num +=1#解析非谣言数据for non_rumor_class_dir in non_rumor_class_dirs:
if(non_rumor_class_dir != '.DS_Store'): with open(original_microblog + non_rumor_class_dir, 'r') as f2:
non_rumor_content = f2.read()
non_rumor_dict = json.loads(non_rumor_content)
all_non_rumor_list.append(non_rumor_label+"\t"+non_rumor_dict["text"]+"\n")
non_rumor_num +=1
print("谣言数据总量为:"+str(rumor_num))print("非谣言数据总量为:"+str(non_rumor_num))
In [ ]
#全部数据进行乱序后写入all_data.txtdata_list_path="/home/aistudio/data/"all_data_path=data_list_path + "all_data.txt"all_data_list = all_rumor_list + all_non_rumor_list
random.shuffle(all_data_list)#在生成all_data.txt之前,首先将其清空with open(all_data_path, 'w') as f:
f.seek(0)
f.truncate()
with open(all_data_path, 'a') as f: for data in all_data_list:
f.write(data)
# 生成数据字典def create_dict(data_path, dict_path):
with open(dict_path, 'w') as f:
f.seek(0)
f.truncate()
dict_set = set() # 读取全部数据
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.readlines() # 把数据生成一个元组
for line in lines:
content = line.split('\t')[-1].replace('\n', '') for s in content:
dict_set.add(s) # 把元组转换成字典,一个字对应一个数字
dict_list = []
i = 0
for s in dict_set:
dict_list.append([s, i])
i += 1
# 添加未知字符
dict_txt = dict(dict_list)
end_dict = {"<unk>": i}
dict_txt.update(end_dict)
end_dict = {"<pad>": i+1}
dict_txt.update(end_dict) # 把这些字典保存到本地中
with open(dict_path, 'w', encoding='utf-8') as f:
f.write(str(dict_txt))
print("数据字典生成完成!")
# 创建序列化表示的数据,并按照一定比例划分训练数据train_list.txt与验证数据eval_list.txtdef create_data_list(data_list_path):
#在生成数据之前,首先将eval_list.txt和train_list.txt清空
with open(os.path.join(data_list_path, 'eval_list.txt'), 'w', encoding='utf-8') as f_eval:
f_eval.seek(0)
f_eval.truncate()
with open(os.path.join(data_list_path, 'train_list.txt'), 'w', encoding='utf-8') as f_train:
f_train.seek(0)
f_train.truncate()
with open(os.path.join(data_list_path, 'dict.txt'), 'r', encoding='utf-8') as f_data:
dict_txt = eval(f_data.readlines()[0]) with open(os.path.join(data_list_path, 'all_data.txt'), 'r', encoding='utf-8') as f_data:
lines = f_data.readlines()
i = 0
maxlen = 0
with open(os.path.join(data_list_path, 'eval_list.txt'), 'a', encoding='utf-8') as f_eval,open(os.path.join(data_list_path, 'train_list.txt'), 'a', encoding='utf-8') as f_train: for line in lines:
words = line.split('\t')[-1].replace('\n', '')
maxlen = max(maxlen, len(words))
label = line.split('\t')[0]
labs = ""
# 每8个 抽取一个数据用于验证
if i % 5 == 0: for s in words:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + label + '\n'
f_eval.write(labs) else: for s in words:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + label + '\n'
f_train.write(labs)
i += 1
print("数据列表生成完成!") print(maxlen)
In [ ]
# 把生成的数据列表都放在自己的总类别文件夹中data_root_path = "/home/aistudio/data/" data_path = os.path.join(data_root_path, 'all_data.txt') dict_path = os.path.join(data_root_path, "dict.txt")# 创建数据字典create_dict(data_path, dict_path)# 创建数据列表create_data_list(data_root_path)In [ ]
def load_vocab(file_path):
fr = open(file_path, 'r', encoding='utf8')
vocab = eval(fr.read()) #读取的str转换为字典
fr.close() return vocab
In [ ]
# 打印前2条训练数据vocab = load_vocab(os.path.join(data_root_path, 'dict.txt'))def ids_to_str(ids):
words = [] for k in ids:
w = list(vocab.keys())[list(vocab.values()).index(int(k))]
words.append(w if isinstance(w, str) else w.decode('ASCII')) return " ".join(words)
file_path = os.path.join(data_root_path, 'train_list.txt')with io.open(file_path, "r", encoding='utf8') as fin:
i = 0
for line in fin:
i += 1
cols = line.strip().split("\t") if len(cols) != 2:
sys.stderr.write("[NOTICE] Error Format Line!") continue
label = int(cols[1])
wids = cols[0].split(",") print(str(i)+":") print('sentence list id is:', wids) print('sentence list is: ', ids_to_str(wids)) print('sentence label id is:', label) print('---------------------------------')
if i == 2: break
vocab = load_vocab(os.path.join(data_root_path, 'dict.txt'))class RumorDataset(paddle.io.Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir
self.all_data = []
with io.open(self.data_dir, "r", encoding='utf8') as fin: for line in fin:
cols = line.strip().split("\t") if len(cols) != 2:
sys.stderr.write("[NOTICE] Error Format Line!") continue
label = []
label.append(int(cols[1]))
wids = cols[0].split(",") if len(wids)>=150:
wids = np.array(wids[:150]).astype('int64')
else:
wids = np.concatenate([wids, [vocab["<pad>"]]*(150-len(wids))]).astype('int64')
label = np.array(label).astype('int64')
self.all_data.append((wids, label))
def __getitem__(self, index):
data, label = self.all_data[index] return data, label def __len__(self):
return len(self.all_data)
batch_size = 32train_dataset = RumorDataset(os.path.join(data_root_path, 'train_list.txt'))
test_dataset = RumorDataset(os.path.join(data_root_path, 'eval_list.txt'))
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = paddle.io.DataLoader(test_dataset, places=paddle.CPUPlace(), return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)#checkprint('=============train_dataset =============')
for data, label in train_dataset: print(data) print(np.array(data).shape) print(label) breakprint('=============test_dataset =============')
for data, label in test_dataset: print(data) print(np.array(data).shape) print(label) break
本项目提供了论文所提出的Conv_FFD模型,其余的对比模型放在model_utils.py文件中
## 导入模型from model_utils import Transformer,LSTM,GRU,CNN
#定义卷积网络class Conv_FFD(nn.Layer):
def __init__(self,dict_dim):
super(Conv_FFD,self).__init__()
self.dict_dim = dict_dim
self.emb_dim = 128
self.hid_dim = 128
self.fc_hid_dim = 96
self.class_dim = 2
self.channels = 1
self.win_size = [3, self.hid_dim]
self.batch_size = 32
self.seq_len = 150
self.embedding = Embedding(self.dict_dim + 1, self.emb_dim, sparse=False)
self.hidden1 = paddle.nn.Conv2D(in_channels=1, #通道数
out_channels=self.hid_dim, #卷积核个数
kernel_size=self.win_size, #卷积核大小
padding=[1, 1]
)
self.relu1 = paddle.nn.ReLU()
self.hidden3 = paddle.nn.MaxPool2D(kernel_size=2, #池化核大小
stride=2) #池化步长2
self.hidden4 = paddle.nn.Linear(128*75, 2) #网络的前向计算过程
def forward(self,input):
#print('输入维度:', input.shape)
x = self.embedding(input)
x = paddle.reshape(x, [32, 1, 150, 128])
x = self.hidden1(x)
x = self.relu1(x) #print('第一层卷积输出维度:', x.shape)
x = self.hidden3(x) #print('池化后输出维度:', x.shape)
#在输入全连接层时,需将特征图拉平会自动将数据拉平.
x = paddle.reshape(x, shape=[self.batch_size, -1])
out = self.hidden4(x) return out
In [ ]
model = Conv_FFD(dict_dim=vocab["<pad>"])
vocab_size = len(vocab) maxlen = 200 seq_len = 200batch_size = 32epochs = 3pad_id = vocab['<pad>'] embed_dim = 128 # Embedding size for each tokennum_heads = 2 # Number of attention headsfeed_dim = 128 # Hidden layer size in feed forward network inside transformerclasses = ['0', '1'] model = Transformer(maxlen,vocab_size,embed_dim,num_heads,feed_dim) paddle.summary(model,(200,128),"int64")
model = LSTM(dict_dim=vocab["<pad>"])
batch_size = 32epochs = 3#词汇表总数vocab_size = len(vocab) + 1print(vocab_size) emb_size = 256#句子固定长度seq_len = 150#补齐词的id编号pad_id = vocab["<pad>"]#类别classes = ['negative', 'positive'] model = GRU(vocab_size=vocab_size,emb_size=emb_size)
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
In [ ]
def train(model):
model.train()
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
steps = 0
Iters, total_loss, total_acc = [], [], []
for epoch in range(3): for batch_id, data in enumerate(train_loader):
steps += 1
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label) if batch_id % 50 == 0:
Iters.append(steps)
total_loss.append(loss.numpy()[0])
total_acc.append(acc.numpy()[0]) print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad() # evaluate model after one epoch
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
*g_acc, *g_loss = np.mean(accuracies), np.mean(losses) print("[validation] accuracy: {}, loss: {}".format(*g_acc, *g_loss))
model.train()
paddle.s*e(model.state_dict(),"model_final.pdparams")
draw_process("trainning loss","red",Iters,total_loss,"trainning loss")
draw_process("trainning acc","green",Iters,total_acc,"trainning acc")
In [ ]
import time
start_time=time.time()
train(model)
end_time=time.time()
running_time=end_time-start_timeprint("running_time is {}".format(running_time))
model_state_dict = paddle.load('model_final.pdparams')
model.set_state_dict(model_state_dict)
model.eval()
accuracies = []
losses = []for batch_id, data in enumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
*g_acc, *g_loss = np.mean(accuracies), np.mean(losses)print("[validation] accuracy: {}, loss: {}".format(*g_acc, *g_loss))
In [ ]
import numpy as npfrom sklearn.metrics import roc_curve, auc, accuracy_score, precision_score, recall_score, f1_score,confusion_matrix
model_state_dict = paddle.load('model_final.pdparams')
model.set_state_dict(model_state_dict)
model.eval()
predictions = []
r = []for batch_id, data in enumerate(test_loader):
sent = data[0]
gt_labels = data[1].numpy() for i in gt_labels:
r.append(i)
results = model(sent) for probs in results: # 映射分类label
idx = np.argmax(probs)
predictions.append(idx)
confusion_matrix(r, predictions)from sklearn.metrics im port classification_report
target_names = ["0","1"]
acc = accuracy_score(r, predictions).round(4)
pre = precision_score(r, predictions).round(4)
rec = recall_score(r, predictions).round(4)
F1 = f1_score(r, predictions).round(4)print('acc:{},pre:{},rec:{},f1:{}'.format(acc,pre,rec,F1))
CR=classification_report(r, predictions, target_names=target_names,digits=4)print(CR)
port classification_report
target_names = ["0","1"]
acc = accuracy_score(r, predictions).round(4)
pre = precision_score(r, predictions).round(4)
rec = recall_score(r, predictions).round(4)
F1 = f1_score(r, predictions).round(4)print('acc:{},pre:{},rec:{},f1:{}'.format(acc,pre,rec,F1))
CR=classification_report(r, predictions, target_names=target_names,digits=4)print(CR)
label_map = {0:"谣言", 1:"不是谣言"}
model_state_dict = paddle.load('model_final.pdparams')
model.set_state_dict(model_state_dict)
model.eval()for batch_id, data in enumerate(test_loader):
sent = data[0]
gt_labels = data[1].numpy()
results = model(sent)
predictions = [] for probs in results: # 映射分类label
idx = np.argmax(probs)
labels = label_map[idx]
predictions.append(labels)
for i,pre in enumerate(predictions): print('数据: {} \n\n预测: {} \n原始标签:{}'.format(ids_to_str(sent[0]).replace(" ", "").replace("<pad>",""), pre, label_map[gt_labels[0][0]])) break
break
步骤一:创建字典,由于中文文本中有超过 4000 个字符,使用如此高维的向量直接对每个字符进行编码仍然很困难。或者,将每个字符转换为具有固定维度的向量是一种理想的编码方案,称为词嵌入。但词嵌入实际上是一种并行矩阵变换,将初始汉字映射为特定的代表向量。这个过程实际上是一个特征学习过程,因为在训练过程中需要学习一些用于映射的参数。所以复现的时候是将中文文本直接以字为单位进行分割,不进行分词。对于每个词Xn,m,可以表示为一个onehot向量vn,m,其维数等于所有潜在汉字B的个数。对于vn,m,其对应字的元素设置为1等元素全部为0。公式如下$$v_{n,m}=\left[\underbrace{1,0,0,\cdots0}_{B-1}\right]$$ 接着,通过一下计算,将vn,m抽象为另一个向量表示Vn,m:
Vn,m=σ(WV⋅vn,m+bV)
其中Wv和bv是要学习的参数,(⋅)是激活函数。
σ(ζ)={ζ,ζ≥00,ζ
这样做的好处是,可以将不同向量都转换成相同维度的向量。
步骤二:用paddle编写训练代码 参数设置全部参照作者论文代码中的设置。
步骤三:模型训练
模型代码比较基础,cpu/gpu抖能跑,速度确实比大模型快很多。
遇到的问题 原代码使用的paddle的接口已经失效,目前最新的已经没有,因此执行的时候报错,将代码改为
self.relu = paddle.fluid.dygraph.Linear(feed_dim, 20, act='relu')
改后
self.linear1 = nn.Linear(feed_dim, 20)self.relu = nn.ReLU()
以上就是基于paddle复现Conv-FFD快速谣言检测模型的详细内容,更多请关注其它相关文章!
# 几个
# seo工资怎么计算
# 学校网站推广方案策划
# 临淄网络营销推广中心
# 通讯网站推广特点
# 武汉seo网站排名优化报价
# 南昌网站SEO优化推广公司
# 水果网站建设游戏app
# 汉中网络推广营销招聘信息
# 手机版网站建设开发
# 凤岗seo推广优化
# 很难
# 放在
# git
# 假新闻
# 带来了
# 是一种
# 社会服务
# 是一个
# 中文网
# 关键词
# type
# udio
# red
# 社交网络
# ai
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
脑虎科技:奔跑在“脑机接口”最前沿 跨界融合取得阶段性成果
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
生成式人工智能如何改变云安全的游戏规则
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
张勇对话多位诺奖得主 人工智能将无处不在
挤爆服务器,北大法律大模型ChatLaw火了:直接告诉你张三怎么判
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
探索人工智能在物联网领域的影响与改变
轻量级的深度学习框架Tinygrad
WHEE上线时间介绍
令人惊叹!AI模型能够以iPhone照片为基础创作诗歌
眼球反射解锁3D世界,黑镜成真!马里兰华人新作炸翻科幻迷
高通发布长期产品计划,为工业和企业物联网产品提供全新组合方案
Midjourney创始人:AI应该成为人类思想的延伸
人工智能:解决劳动力短缺的关键策略
基于预训练模型的金融事件分析及应用
百度举办AIGC创作沙龙,现场传授AI绘画“咒语”技巧
新闻传闻:迪士尼可能采用人工智能来控制电影制作成本
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
“黑科技”亮相大湾区轨交论坛 智慧交通迈向“强AI”
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
“具身智能”引爆机器人产业,看绝影Lite3/X20四足机器人有何特别之处?
AI取代人工先拿教育行业开刀?美版“作业帮”启动裁员
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
深企派遣无人机救援队赴京津冀开展防汛救灾任务
再度重仓 AI 赛道,SaaS 巨头 Salesforce 扩大 AIGC 风投基金规模
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
国网辉南供电:无人机空中巡检 全力护航端午佳节
微软AR/VR专利提出使用时间复用谐振驱动产生双极性电源
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
旷视入选北京市通用人工智能产业创新伙伴计划
机器人 展才能
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
联想戴炜:以全栈AI加速CT与IT融合,共建高质量算力网络
掌阅科技入选北京市通用人工智能产业创新伙伴计划第二批成员名单
猿辅导推出Motiff,整合三大AI功能,助力UI设计生产力革新
微软推出人工智能模型 CoDi,可互动和生成多模态内容
Goodnotes 6推出,带来多项全新AI功能,让电子笔记更智能
利亚德加码AI战略,与光年无限图灵机器人全面开展AI研发业务合作
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
人工智能改变网络安全和用户体验的三种方式
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
中国电信AI能力通过国家级金融领域权威认证并荣膺AI国际头部竞赛冠军
令人震惊的特斯拉机器人
热点 | 人工智能黄金时代开启
2025-07-16

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 port classification_report
target_names = ["0","1"]
acc = accuracy_score(r, predictions).round(4)
pre = precision_score(r, predictions).round(4)
rec = recall_score(r, predictions).round(4)
F1 = f1_score(r, predictions).round(4)print('acc:{},pre:{},rec:{},f1:{}'.format(acc,pre,rec,F1))
CR=classification_report(r, predictions, target_names=target_names,digits=4)print(CR)
port classification_report
target_names = ["0","1"]
acc = accuracy_score(r, predictions).round(4)
pre = precision_score(r, predictions).round(4)
rec = recall_score(r, predictions).round(4)
F1 = f1_score(r, predictions).round(4)print('acc:{},pre:{},rec:{},f1:{}'.format(acc,pre,rec,F1))
CR=classification_report(r, predictions, target_names=target_names,digits=4)print(CR)