做目标检测就一定需要 FPN 吗?来自 Facebook AI Research 的 Yanghao Li、何恺明等研究者在 ECCV2025上的一篇论文,证明了将普通的、非分层的视觉 Transformer 作为主干网络进行目标检测的可行性。他们希望这项研究能够引起大家对普通主干检测器的关注。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

做目标检测就一定需要 FPN 吗?来自 Facebook AI Research 的 Yanghao Li、何恺明等研究者在 ECCV2025上的一篇论文,证明了将普通的、非分层的视觉 Transformer 作为主干网络进行目标检测的可行性。他们希望这项研究能够引起大家对普通主干检测器的关注。
当前的目标检测器通常由一个与检测任务无关的主干特征提取器和一组包含检测专用先验知识的颈部和头部组成。颈部 / 头部中的常见组件可能包括感兴趣区域(RoI)操作、区域候选网络(RPN)或锚、特征金字塔网络(FPN)等。如果用于特定任务的颈部 / 头部的设计与主干的设计解耦,它们可以并行发展。从经验上看,目标检测研究受益于对通用主干和检测专用模块的大量独立探索。长期以来,由于卷积网络的实际设计,这些主干一直是多尺度、分层的架构,这严重影响了用于多尺度(如 FPN)目标检测的颈 / 头的设计。
在过去的一年里,视觉 Transformer(ViT)已经成为视觉识别的强大支柱。与典型的 ConvNets 不同,最初的 ViT 是一种简单的、非层次化的架构,始终保持单一尺度的特征图。它的「极简」追求在应用于目标检测时遇到了挑战,例如,我们如何通过上游预训练的简单主干来处理下游任务中的多尺度对象?简单 ViT 用于高分辨率图像检测是否效率太低?放弃这种追求的一个解决方案是在主干中重新引入分层设计。这种解决方案,例如 Swin Transformer 和其他网络,可以继承基于 ConvNet 的检测器设计,并已取得成功。
在这项工作中,何恺明等研究者追求的是一个不同的方向:探索仅使用普通、非分层主干的目标检测器。如果这一方向取得成功,仅使用原始 ViT 主干进行目标检测将成为可能。在这一方向上,预训练设计将与微调需求解耦,上游与下游任务的独立性将保持,就像基于 ConvNet 的研究一样。这一方向也在一定程度上遵循了 ViT 的理念,即在追求通用特征的过程中减少归纳偏置。由于非局部自注意力计算可以学习平移等变特征,它们也可以从某种形式的监督或自我监督预训练中学习尺度等变特征。
研究者表示,在这项研究中,他们的目标不是开发新的组件,而是通过最小的调整克服上述挑战。具体来说,他们的检测器仅从一个普通 ViT 主干的最后一个特征图构建一个简单的特征金字塔(如下图所示)。这一方案放弃了 FPN 设计和分层主干的要求。为了有效地从高分辨率图像中提取特征,他们的检测器使用简单的非重叠窗口注意力(没有 shifting)。他们使用少量的跨窗口块来传播信息,这些块可以是全局注意力或卷积。这些调整只在微调过程中进行,不会改变预训练。
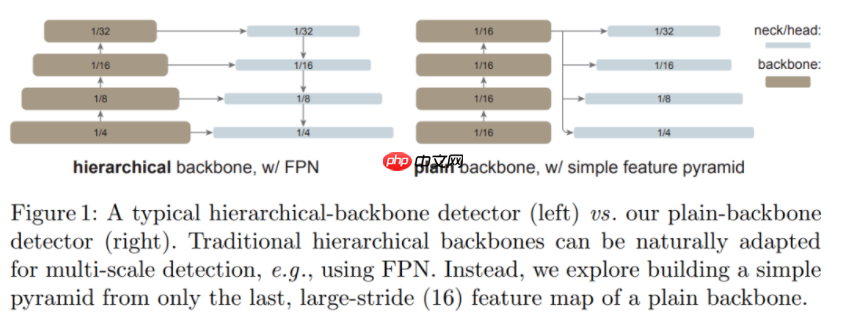
这种简单的设计收获了令人惊讶的结果。研究者发现,在使用普通 ViT 主干的情况下,FPN 的设计并不是必要的,它的好处可以通过由大步幅 (16)、单一尺度图构建的简单金字塔来有效地获得。他们还发现,只要信息能在少量的层中很好地跨窗口传播,窗口注意力就够用了。
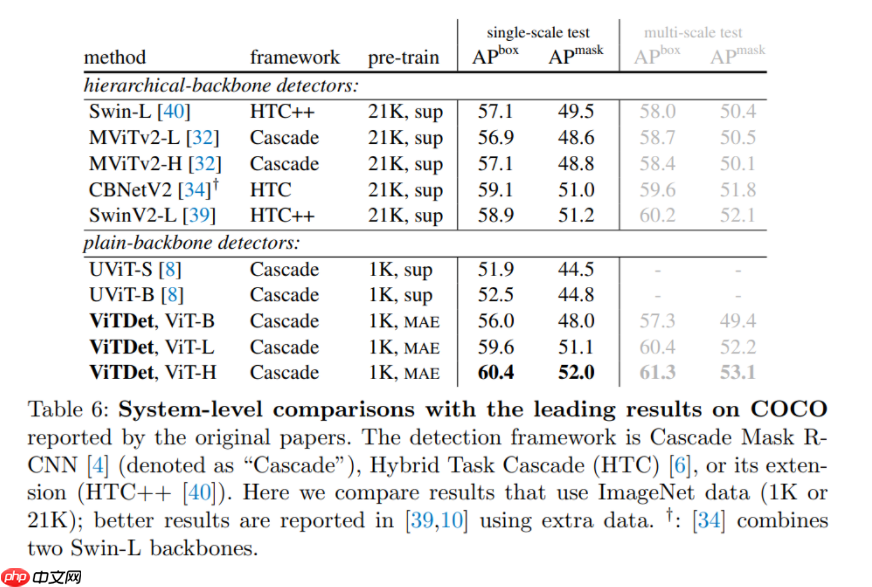
更令人惊讶的是,在某些情况下,研究者开发的名为「ViTDet」的普通主干检测器可以媲美领先的分层主干检测器(如 Swin、MViT)。通过掩蔽自编码器(MAE)预训练,他们的普通主干检测器可以优于在 ImageNet-1K/21K 上进行有监督预训练的分层检测器(如下图所示)。 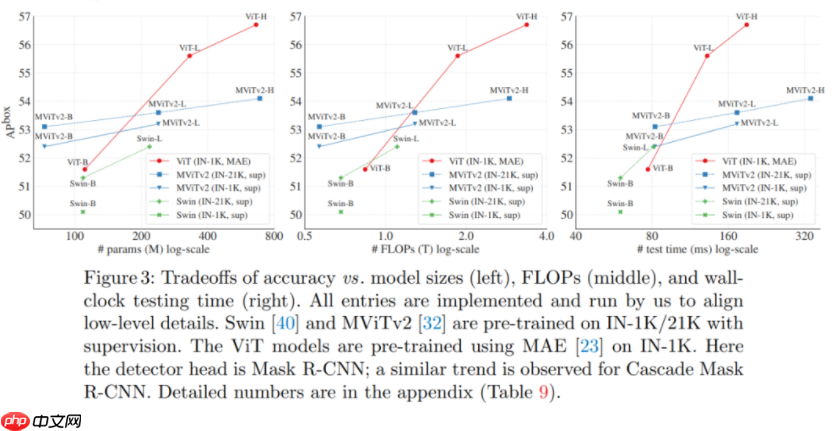
在较大尺寸的模型上,这种增益要更加显著。该检测器的优秀性能是在不同的目标检测器框架下观察到的,包括 Mask R-CNN、Cascade Mask R-CNN 以及它们的增强版本。
在 COCO 数据集上的实验结果表明,一个使用无标签 ImageNet-1K 预训练、带有普通 ViT-Huge 主干的 ViTDet 检测器的 AP^box 可以达到 61.3。他们还在长尾 LVIS 检测数据集上展示了 ViTDet 颇具竞争力的结果。虽然这些强有力的结果可能部分来自 MAE 预训练的有效性, 但这项研究表明,普通主干检测器可能是有前途的,这挑战了分层主干在目标检测中的根深蒂固的地位。
该研究的目标是消除对主干网络的分层约束,并使用普通主干网络进行目标检测。因此,该研究的目标是用最少的改动,让简单的主干网络在微调期间适应目标检测任务。经过改动之后,原则上我们可以应用任何检测器头(detector head),研究者选择使用 Mask R-CNN 及其扩展。
2.1 简单的特征金字塔
FPN 是构建用于目标检测的 in-network 金字塔的常见解决方案。如果主干网络是分层的,FPN 的动机就是将早期高分辨率的特征和后期更强的特征结合起来。这在 FPN 中是通过自上而下(top-down)和横向连接来实现的,如下图左边部分所示。 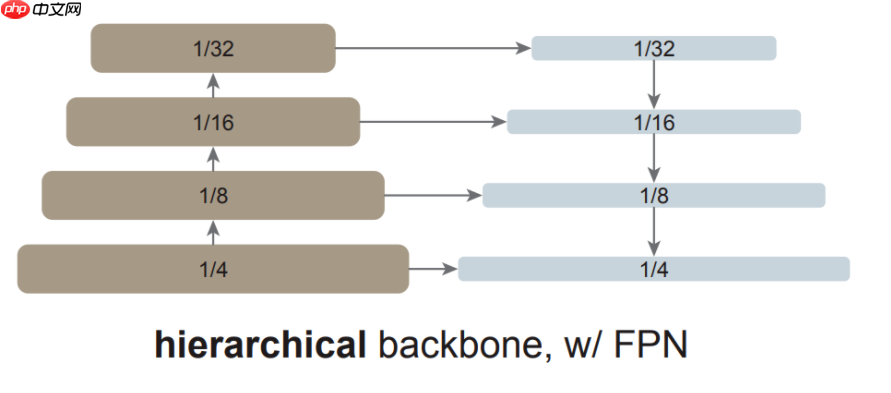
如果主干网络不是分层网络,那么 FPN 动机的基础就会消失,因为主干网络中的所有特征图都具有相同的分辨率。该研究仅使用主干网络中的最后一张特征图,因为它应该具有最强大的特征。
研究者对最后一张特征图并行应用一组卷积或反卷积来生成多尺度特征图。具体来说,他们使用的是尺度为 1/16(stride = 16 )的默认 ViT 特征图,该研究可如下图右边所示,这个过程被称为「简单的特征金字塔」。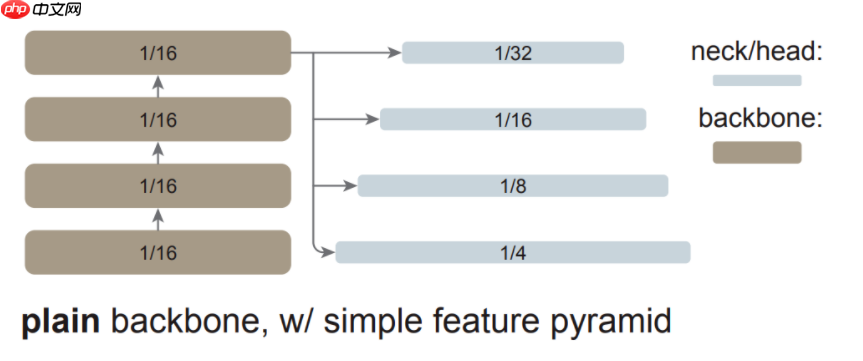
从单张特征图构建多尺度特征图的策略与 SSD 的策略有关,但该研究的场景涉及对深度、低分辨率的特征图进行上采样。在分层主干网络中,上采样通常用横向连接进行辅助,但研究者通过实验发现,在普通 ViT 主干网络中横向连接并不是必需的,简单的反卷积就足够了。研究者猜想这是因为 ViT 可以依赖位置嵌入来编码位置,并且高维 ViT patch 嵌入不一定会丢弃信息。
如下图所示,该研究将这种简单的特征金字塔与同样建立在普通主干网络上的两个 FPN 变体进行比较。在第一个变体中,主干网络被人为地划分为多个阶段,以模仿分层主干网络的各个阶段,并应用横向和自上而下的连接(图(a))。第二个变体与第一个变体类似,但仅使用最后一张特征图(图(b))。该研究表明这些 FPN 变体不是必需的。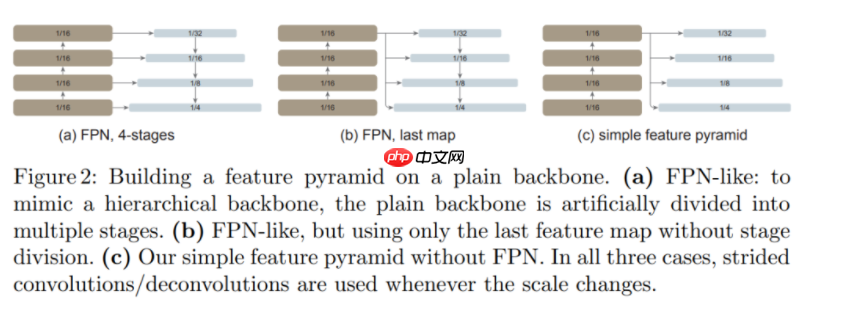
 新快购物系统
新快购物系统
新快购物系统是集合目前网络所有购物系统为参考而开发,不管从速度还是安全我们都努力做到最好,此版虽为免费版但是功能齐全,无任何错误,特点有:专业的、全面的电子商务解决方案,使您可以轻松实现网上销售;自助式开放性的数据平台,为您提供充满个性化的设计空间;功能全面、操作简单的远程管理系统,让您在家中也可实现正常销售管理;严谨实用的全新商品数据库,便于查询搜索您的商品。
 0
查看详情
0
查看详情

目标检测器受益于高分辨率输入图像,但在整个主干网络中,计算全局自注意力对于内存的要求非常高,而且速度很慢。该研究重点关注预训练主干网络执行全局自注意力的场景,然后在微调期间适应更高分辨率的输入。这与最近使用主干网络预训练直接修改注意力计算的方法形成对比。该研究的场景使得研究者能够使用原始 ViT 主干网络进行检测,而无需重新设计预训练架构。
该研究探索了使用跨窗口块的窗口注意力。在微调期间,给定高分辨率特征图,该研究将其划分为常规的非重叠窗口。在每个窗口内计算自注意力,这在原始 Transformer 中被称为「受限」自注意力。
与 Swin 不同,该方法不会跨层「移动(shift)」窗口。为了允许信息传播,该研究使用了极少数(默认为 4 个)可跨窗口的块。研究者将预训练的主干网络平均分成 4 个块的子集(例如对于 24 块的 ViT-L,每个子集中包含 6 个),并在每个子集的最后一个块中应用传播策略。研究者分析了如下两种策略:(1)全局传播。该策略在每个子集的最后一个块中执行全局自注意力。由于全局块的数量很少,内存和计算成本是可行的。(2)卷积传播。该策略在每个子集之后添加一个额外的卷积块来作为替代。卷积块是一个残差块,由一个或多个卷积和一个 identity shortcut 组成。该块中的最后一层被初始化为零,因此该块的初始状态是一个 identity。将块初始化为 identity 使得该研究能够将其插入到预训练主干网络中的任何位置,而不会破坏主干网络的初始状态。
这种主干网络的调整非常简单,并且使检测微调与全局自注意力预训练兼容,也就没有必要重新设计预训练架构。
配置文件位置在PaddleDetection/configs/vitdet/videtvitb.yml
核心代码位置在PaddleDetection/ppdet/modeling/backbones/vit.py
代码基于PaddleDetection检测套件,大家如果对PaddleDetection感兴趣,可以到GITHUB上了解一下
@register@serializableclass SimpleFeaturePyramid(nn.Layer):
"""
This module implements SimpleFeaturePyramid in :paper:`vitdet`.
It creates pyramid features built on top of the input feature map.
"""
def __init__(
self,
net,
out_channels,
scale_factors,
in_feature = None,
top_block=None,
norm="LN",
square_pad=0, ):
"""
Args:
net (Backbone): module representing the subnetwork backbone.
Must be a subclass of :class:`Backbone`.
in_feature (str): names of the input feature maps coming
from the net.
out_channels (int): number of channels in the output feature maps.
scale_factors (list[float]): list of scaling factors to upsample or downsample
the input features for creating pyramid features.
top_block (nn.Module or None): if provided, an extra operation will
be performed on the output of the last (smallest resolution)
pyramid output, and the result will extend the result list. The top_block
further downsamples the feature map. It must h*e an attribute
"num_levels", meaning the number of extra pyramid levels added by
this block, and "in_feature", which is a string representing
its input feature (e.g., p5).
norm (str): the normalization to use.
square_pad (int): If > 0, require input images to be padded to specific square size.
"""
super(SimpleFeaturePyramid, self).__init__()
scale_factors = eval(scale_factors)
self.scale_factors = scale_factors
net = ViT(**net)
input_shapes = net.output_shape()
in_feature = net._out_features[0]
strides = [int(input_shapes[in_feature].stride / scale) for scale in scale_factors]
_assert_strides_are_log2_contiguous(strides)
dim = input_shapes[in_feature].channels
self.stages = []
use_bias = (norm == "") for idx, scale in enumerate(scale_factors):
out_dim = dim if scale == 4.0:
layers = [
ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2),
Transpose(),
get_norm(norm, dim // 2),
nn.GELU(),
DTranspose(),
ConvTranspose2d(dim // 2, dim // 4, kernel_size=2, stride=2),
]
out_dim = dim // 4
elif scale == 2.0:
layers = [ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2)]
out_dim = dim // 2
elif scale == 1.0:
layers = [] elif scale == 0.5:
layers = [nn.MaxPool2D(kernel_size=2, stride=2)] else: raise NotImplementedError(f"scale_factor={scale} is not supported yet.")
layers.extend(
[
Conv2d(
out_dim,
out_channels,
kernel_size=1,
use_bias=use_bias,
norm=get_norm(norm, out_channels),
),
Conv2d(
out_channels,
out_channels,
kernel_size=3,
use_bias=use_bias,
norm=get_norm(norm, out_channels),
),
]
)
layers = nn.Sequential(*layers)
stage = int(math.log2(strides[idx]))
self.add_sublayer(f"simfp_{stage}", layers)
self.stages.append(layers)
self.net = net
self.in_feature = in_feature
top_block = eval(top_block)()
self.top_block = top_block # Return feature names are "p<stage>", like ["p2", "p3", ..., "p6"]
self._out_feature_strides = {"p{}".format(int(math.log2(s))): s for s in strides} # top block output feature maps.
if self.top_block is not None: for s in range(stage, stage + self.top_block.num_levels):
self._out_feature_strides["p{}".format(s + 1)] = 2 ** (s + 1)
self._out_features = list(self._out_feature_strides.keys())
self._out_feature_channels = {k: out_channels for k in self._out_features}
self._size_divisibility = strides[-1]
self._square_pad = square_pad @property
def padding_constraints(self):
return { "size_divisiblity": self._size_divisibility, "square_size": self._square_pad,
} def forward(self, x):
"""
Args:
x: Tensor of shape (N,C,H,W). H, W must be a multiple of ``self.size_divisibility``.
Returns:
dict[str->Tensor]:
mapping from feature map name to pyramid feature map tensor
in high to low resolution order. Returned feature names follow the FPN
convention: "p<stage>", where stage has stride = 2 ** stage e.g.,
["p2", "p3", ..., "p6"].
"""
bottom_up_features = self.net(x["image"]) #这里backbone部分,也就是ViT
features = bottom_up_features[self.in_feature]
results = [] for stage in self.stages:
results.append(stage(features)) # 这里就是反卷积部分
if self.top_block is not None: # 这里就是论文中池化部分
if self.top_block.in_feature in bottom_up_features:
top_block_in_feature = bottom_up_features[self.top_block.in_feature] else:
top_block_in_feature = results[self._out_features.index(self.top_block.in_feature)]
results.extend(self.top_block(top_block_in_feature)) assert len(self._out_features) == len(results) return results #return {f: res for f, res in zip(self._out_features, results)} @property
def out_shape(self):
return [
ShapeSpec(
channels=self._out_feature_channels[i], stride=self._out_feature_strides[i]) for i in self._out_features
]
接着就是特征提取网络ViT 这个和Vision Transformer多了个window_partition,其余部分是一致的
@register@serializableclass ViT(nn.Layer):
"""
This module implements Vision Transformer (ViT) backbone in :paper:`vitdet`.
"Exploring Plain Vision Transformer Backbones for Object Detection",
https://arxiv.org/abs/2203.16527
"""
def __init__(
self,
img_size=1024,
patch_size=16,
in_chans=3,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.0,
qkv_bias=True,
drop_path_rate=0.0,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU,
use_abs_pos=True,
use_rel_pos=False,
rel_pos_zero_init=True,
window_size=0,
window_block_indexes=(),
residual_block_indexes=(),
use_act_checkpoint=False,
pretrain_img_size=224,
pretrain_use_cls_token=True,
out_feature="last_feat", ):
"""
Args:
img_size (int): Input image size.
patch_size (int): Patch size.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
depth (int): Depth of ViT.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
drop_path_rate (float): Stochastic depth rate.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_abs_pos (bool): If True, use absolute positional embeddings.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks.
window_block_indexes (list): Indexes for blocks using window attention.
residual_block_indexes (list): Indexes for blocks using conv propagation.
use_act_checkpoint (bool): If True, use activation checkpointing.
pretrain_img_size (int): input image size for pretraining models.
pretrain_use_cls_token (bool): If True, pretrainig models use class token.
out_feature (str): name of the feature from the last block.
"""
super().__init__()
self.pretrain_use_cls_token = pretrain_use_cls_token
self.patch_embed = PatchEmbed(
kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size),
in_chans=in_chans,
embed_dim=embed_dim,
) if use_abs_pos: # Initialize absolute positional embedding with pretrain image size.
num_patches = (pretrain_img_size // patch_size) * (pretrain_img_size // patch_size)
num_positions = (num_patches + 1) if pretrain_use_cls_token else num_patches
self.pos_embed = add_parameter(self,paddle.ones((1, num_positions, embed_dim))) else:
self.pos_embed = None
# stochastic depth decay rule
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, depth)]
self.blocks = nn.LayerList() for i in range(depth):
block = Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop_path=dpr[i],
norm_layer=norm_layer,
act_layer=act_layer,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
window_size=window_size if i in window_block_indexes else 0,
use_residual_block=i in residual_block_indexes,
input_size=(img_size // patch_size, img_size // patch_size),
) if use_act_checkpoint:
block = checkpoint_wrapper(block)
self.blocks.append(block)
self._out_feature_channels = {out_feature: embed_dim}
self._out_feature_strides = {out_feature: patch_size}
self._out_features = [out_feature] if self.pos_embed is not None:
trunc_normal_(self.pos_embed)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros(m.bias) elif isinstance(m, nn.LayerNorm):
zeros(m.bias)
ones(m.weight) def forward(self, x):
x = self.patch_embed(x) if self.pos_embed is not None:
x = x + get_abs_pos(
self.pos_embed, self.pretrain_use_cls_token, (x.shape[1], x.shape[2])
) for blk in self.blocks:
x = blk(x)
outputs = {self._out_features[0]: x.transpose((0, 3, 1, 2))} return outputs def output_shape(self):
"""
Returns:
dict[str->ShapeSpec]
"""
# this is a backward-compatible default
return {
name: ShapeSpec(
channels=self._out_feature_channels[name], stride=self._out_feature_strides[name]
) for name in self._out_features
}#这里展示window_partition 和window_unpartition 代码# 简单来说就是将图片分成若干个不重叠的windowsdef window_unpartition(windows, window_size, pad_hw, hw):
"""
Window unpartition into original sequences and removing padding.
Args:
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
window_size (int): window size.
pad_hw (Tuple): padded height and width (Hp, Wp).
hw (Tuple): original height and width (H, W) before padding.
Returns:
x: unpartitioned sequences with [B, H, W, C].
"""
Hp, Wp = pad_hw
H, W = hw
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
x = windows.reshape((B, Hp // window_size, Wp // window_size, window_size, window_size, -1))
x = x.transpose((0, 1, 3, 2, 4, 5)).reshape((B, Hp, Wp, -1)) if Hp > H or Wp > W:
x = x[:, :H, :W, :] return xdef window_partition(x, window_size):
"""
Partition into non-overlapping windows with padding if needed.
Args:
x (tensor): input tokens with [B, H, W, C].
window_size (int): window size.
Returns:
windows: windows after partition with [B * num_windows, window_size, window_size, C].
(Hp, Wp): padded height and width before partition
"""
B, H, W, C = x.shape
pad_h = (window_size - H % window_size) % window_size
pad_w = (window_size - W % window_size) % window_size if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, pad_w, 0, pad_h),data_format = 'NHWC')
Hp, Wp = H + pad_h, W + pad_w
x = x.reshape((B, Hp // window_size, window_size, Wp // window_size, window_size, C))
windows = x.transpose((0, 1, 3, 2, 4, 5)).reshape((-1, window_size, window_size, C)) return windows, (Hp, Wp)
这里就是VIT里面核心的block,包括Self-attention以及上面提到的window_partition
class Attention(nn.Layer):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim,
num_heads=8,
qkv_bias=True,
use_rel_pos=False,
rel_pos_zero_init=True,
input_size=None, ):
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_b ias (bool: If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos if self.use_rel_pos: # initialize relative positional embeddings
self.rel_pos_h = add_parameter(self,paddle.zeros((2 * input_size[0] - 1, head_dim)))
self.rel_pos_w = add_parameter(self,paddle.zeros((2 * input_size[1] - 1, head_dim))) if not rel_pos_zero_init:
trunc_normal_(self.rel_pos_h)
trunc_normal_(self.rel_pos_w) def forward(self, x):
B, H, W, _ = x.shape # qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape((B, H * W, 3, self.num_heads, -1)).transpose((2, 0, 3, 1, 4)) # q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape((3, B * self.num_heads, H * W, -1)).unbind(0)
attn = (q * self.scale) @ k.transpose((0, 2, 1)) if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = F.softmax(attn,axis = -1)
x = (attn @ v).reshape((B, self.num_heads, H, W, -1)).transpose((0, 2, 3, 1, 4)).reshape((B, H, W, -1))
x = self.proj(x) return xclass Block(nn.Layer):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=True,
drop_path=0.0,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU,
use_rel_pos=False,
rel_pos_zero_init=True,
window_size=0,
use_residual_block=False,
input_size=None, ):
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
drop_path (float): Stochastic depth rate.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then not
use window attention.
use_residual_block (bool): If True, use a residual block after the MLP block.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.norm1 = norm_layer(dim,epsilon = 1e-6)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
self.window_size = window_size
self.use_residual_block = use_residual_block if use_residual_block: # Use a residual block with bottleneck channel as dim // 2
self.residual = ResBottleneckBlock(
in_channels=dim,
out_channels=dim,
bottleneck_channels=dim // 2,
norm="LN",
act_layer=act_layer,
) def forward(self, x):
shortcut = x
x = self.norm1(x) # Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x) # Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) if self.use_residual_block:
x = self.residual(x.transpose((0, 3, 1, 2))).transpose((0, 2, 3, 1)) return x
ias (bool: If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos if self.use_rel_pos: # initialize relative positional embeddings
self.rel_pos_h = add_parameter(self,paddle.zeros((2 * input_size[0] - 1, head_dim)))
self.rel_pos_w = add_parameter(self,paddle.zeros((2 * input_size[1] - 1, head_dim))) if not rel_pos_zero_init:
trunc_normal_(self.rel_pos_h)
trunc_normal_(self.rel_pos_w) def forward(self, x):
B, H, W, _ = x.shape # qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape((B, H * W, 3, self.num_heads, -1)).transpose((2, 0, 3, 1, 4)) # q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape((3, B * self.num_heads, H * W, -1)).unbind(0)
attn = (q * self.scale) @ k.transpose((0, 2, 1)) if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = F.softmax(attn,axis = -1)
x = (attn @ v).reshape((B, self.num_heads, H, W, -1)).transpose((0, 2, 3, 1, 4)).reshape((B, H, W, -1))
x = self.proj(x) return xclass Block(nn.Layer):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=True,
drop_path=0.0,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU,
use_rel_pos=False,
rel_pos_zero_init=True,
window_size=0,
use_residual_block=False,
input_size=None, ):
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
drop_path (float): Stochastic depth rate.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then not
use window attention.
use_residual_block (bool): If True, use a residual block after the MLP block.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.norm1 = norm_layer(dim,epsilon = 1e-6)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
self.window_size = window_size
self.use_residual_block = use_residual_block if use_residual_block: # Use a residual block with bottleneck channel as dim // 2
self.residual = ResBottleneckBlock(
in_channels=dim,
out_channels=dim,
bottleneck_channels=dim // 2,
norm="LN",
act_layer=act_layer,
) def forward(self, x):
shortcut = x
x = self.norm1(x) # Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x) # Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) if self.use_residual_block:
x = self.residual(x.transpose((0, 3, 1, 2))).transpose((0, 2, 3, 1)) return x
In [1]
# 解压数据集# !unzip -d data/ data/data97273/train2017.zip!unzip -d data/ data/data97273/val2017.zip!unzip -d data/ data/data97273/annotations_trainval2017.zipIn [2]
%cd /home/aistudio/PaddleDetection/
/home/aistudio/PaddleDetectionIn [3]
!pip install -r requirements.txtIn [4]
!python setup.py installIn [8]
#开启训练# 由于官方使用A100进行训练,V100显存不够,因此想要训练的同学要么减小target size,要么减小reader.yml中的scale range的上限。# 我们这里采用减小scale range 上限# 学习率要调一下,配置文件里面学习率是8卡的!python -m paddle.distributed.launch --gpus 0 tools/train.py -c configs/vitdet/vitdet_vitb.yml --evalIn [5]
#开启验证!python tools/eval.py -c configs/vitdet/vitdet_vitb.yml -o weights=/home/aistudio/data/data158992/VITD_B.pdparams
W0722 21:35:52.054483 1891 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0722 21:35:52.070559 1891 gpu_resources.cc:91] device: 0, cuDNN Version: 7.6. loading annotations into memory... Done (t=0.93s) creating index... index created! [07/22 21:35:59] ppdet.utils.checkpoint INFO: Finish loading model weights: /home/aistudio/data/data158992/VITD_B.pdparams [07/22 21:36:01] ppdet.engine INFO: Eval iter: 0 [07/22 21:36:19] ppdet.engine INFO: Eval iter: 100 [07/22 21:36:37] ppdet.engine INFO: Eval iter: 200 [07/22 21:36:54] ppdet.engine INFO: Eval iter: 300 [07/22 21:37:12] ppdet.engine INFO: Eval iter: 400 [07/22 21:37:29] ppdet.engine INFO: Eval iter: 500 [07/22 21:37:47] ppdet.engine INFO: Eval iter: 600 [07/22 21:38:05] ppdet.engine INFO: Eval iter: 700 [07/22 21:38:23] ppdet.engine INFO: Eval iter: 800 [07/22 21:38:40] ppdet.engine INFO: Eval iter: 900 [07/22 21:38:58] ppdet.engine INFO: Eval iter: 1000 [07/22 21:39:15] ppdet.engine INFO: Eval iter: 1100 [07/22 21:39:33] ppdet.engine INFO: Eval iter: 1200 [07/22 21:39:51] ppdet.engine INFO: Eval iter: 1300 [07/22 21:40:08] ppdet.engine INFO: Eval iter: 1400 [07/22 21:40:27] ppdet.engine INFO: Eval iter: 1500 [07/22 21:40:45] ppdet.engine INFO: Eval iter: 1600 [07/22 21:41:03] ppdet.engine INFO: Eval iter: 1700 [07/22 21:41:21] ppdet.engine INFO: Eval iter: 1800 [07/22 21:41:39] ppdet.engine INFO: Eval iter: 1900 [07/22 21:41:57] ppdet.engine INFO: Eval iter: 2000 [07/22 21:42:16] ppdet.engine INFO: Eval iter: 2100 [07/22 21:42:33] ppdet.engine INFO: Eval iter: 2200 [07/22 21:42:51] ppdet.engine INFO: Eval iter: 2300 [07/22 21:43:10] ppdet.engine INFO: Eval iter: 2400 [07/22 21:43:28] ppdet.engine INFO: Eval iter: 2500 [07/22 21:43:46] ppdet.engine INFO: Eval iter: 2600 [07/22 21:44:03] ppdet.engine INFO: Eval iter: 2700 [07/22 21:44:22] ppdet.engine INFO: Eval iter: 2800 [07/22 21:44:39] ppdet.engine INFO: Eval iter: 2900 [07/22 21:44:57] ppdet.engine INFO: Eval iter: 3000 [07/22 21:45:14] ppdet.engine INFO: Eval iter: 3100 [07/22 21:45:33] ppdet.engine INFO: Eval iter: 3200 [07/22 21:45:52] ppdet.engine INFO: Eval iter: 3300 [07/22 21:46:10] ppdet.engine INFO: Eval iter: 3400 [07/22 21:46:28] ppdet.engine INFO: Eval iter: 3500 [07/22 21:46:46] ppdet.engine INFO: Eval iter: 3600 [07/22 21:47:03] ppdet.engine INFO: Eval iter: 3700 [07/22 21:47:21] ppdet.engine INFO: Eval iter: 3800 [07/22 21:47:39] ppdet.engine INFO: Eval iter: 3900 [07/22 21:47:57] ppdet.engine INFO: Eval iter: 4000 [07/22 21:48:16] ppdet.engine INFO: Eval iter: 4100 [07/22 21:48:36] ppdet.engine INFO: Eval iter: 4200 [07/22 21:48:55] ppdet.engine INFO: Eval iter: 4300 [07/22 21:49:13] ppdet.engine INFO: Eval iter: 4400 [07/22 21:49:30] ppdet.engine INFO: Eval iter: 4500 [07/22 21:49:48] ppdet.engine INFO: Eval iter: 4600 [07/22 21:50:05] ppdet.engine INFO: Eval iter: 4700 [07/22 21:50:23] ppdet.engine INFO: Eval iter: 4800 [07/22 21:50:42] ppdet.engine INFO: Eval iter: 4900 [07/22 21:50:53] ppdet.metrics.metrics INFO: The bbox result is s*ed to bbox.json. loading annotations into memory... Done (t=0.94s) creating index... index created! [07/22 21:50:54] ppdet.metrics.coco_utils INFO: Start evaluate... Loading and preparing results... DONE (t=1.56s) creating index... index created! Running per image evaluation... Evaluate annotation type *bbox* DONE (t=33.42s). Accumulating evaluation results... DONE (t=4.06s). Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.505 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.712 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.560 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.330 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.546 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.655 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.380 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.602 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.629 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.443 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.670 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.774 [07/22 21:51:35] ppdet.metrics.metrics INFO: The mask result is s*ed to mask.json. loading annotations into memory... Done (t=0.45s) creating index... index created! [07/22 21:51:36] ppdet.metrics.coco_utils INFO: Start evaluate... Loading and preparing results... DONE (t=1.68s) creating index... index created! Running per image evaluation... Evaluate annotation type *segm* DONE (t=35.58s). Accumulating evaluation results... DONE (t=4.12s). Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.453 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.690 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.494 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.254 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.483 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.634 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.351 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.548 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.571 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.385 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.611 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.722 [07/22 21:52:18] ppdet.engine INFO: Total sample number: 4952, *erge FPS: 5.550909096883424In [5]
#VITDe-L模型验证!python tools/eval.py -c configs/vitdet/vitdet_vitl.yml -o weights=/home/aistudio/data/data158992/VITD_L.pdparams
这里再给大家展示一下我复现的VITDet-L模型效果。 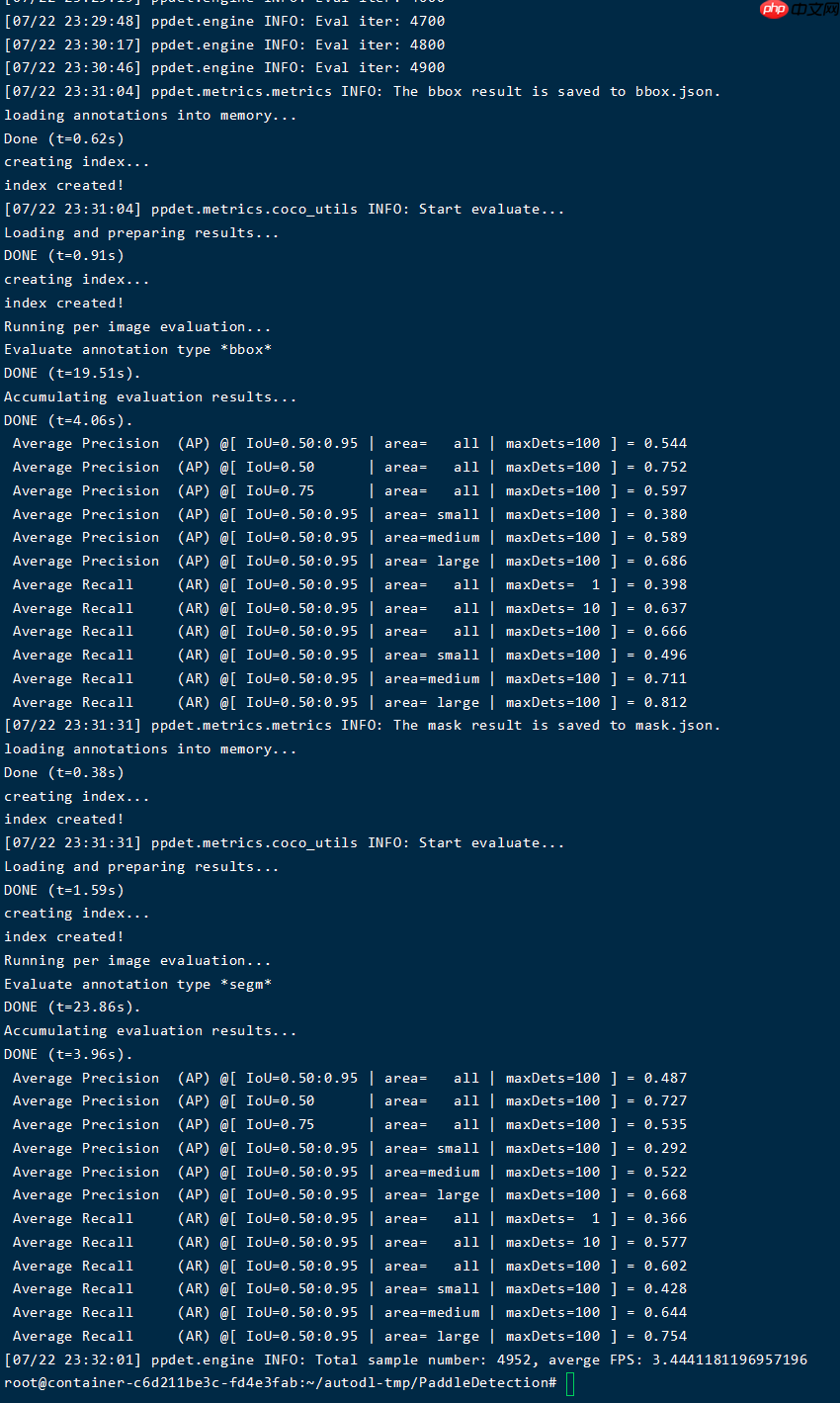
VITDet其他模型大家可以使用convert_weight.py获得paddle权重
运行代码 python tools/infer.py -c configs/vitdet/vitdet_vitl.yml --infer_img=/path/img -o weights=/home/aistudio/data/data158992/VITD_L.pdparams 效果看出VITDet还是非常不错的
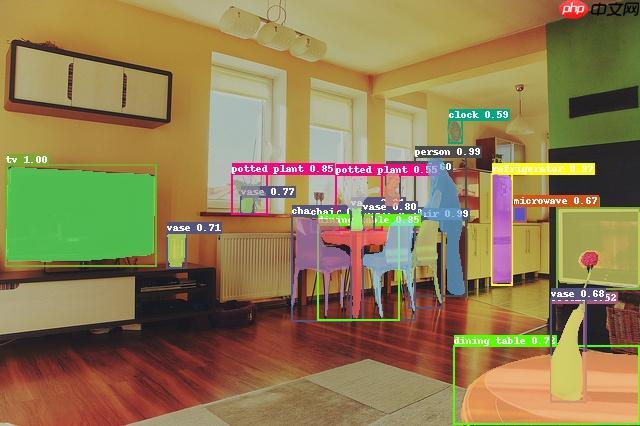


以上就是何恺明新作品:VITDet的详细内容,更多请关注其它相关文章!
# 的是
# 常熟自己建设网站
# 什么是百度推广营销平台
# 关键词排名哪家做的好
# 泰安网站建设优化诊断
# 林州网站seo
# 惠州市有实力的网站推广
# 辽中区网站建设价钱
# 案例城市级营销推广
# 自己做一个网站做推广
# 重庆市的seo公司
# 是一个
# 新快
# 一言
# 这一
# 如下图
# python
# 购物系统
# 所示
# 他们的
# 中文网
# type
# fig
# udio
# follow
# igs
# ai
# facebook
# cad
# windows
# git
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
小米又拿下国际比赛第一:AI翻译立功
如何提高集群协作效率?中外团队合作研发基于均值偏移的机器人队形控制策略
“痴迷”元宇宙,魔珐科技想做什么?
AIGC浪潮下,联想集团再加码计算与人工智能
OpenAI宣布组建新团队 以控制“超级智能”人工智能
有远见!华为四年前注册商标Vision Pro:苹果AR国内要改名
机器人 展才能
稿见AI助手:提升写作效率与质量的必备工具
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
“踩油门,也要会踩刹车” 互联网企业高管谈人工智能发展
跑不动的元宇宙,虚拟世界比现实更冷酷
无人机自主巡检为高海拔输电线路运维添“新彩”
人工智能正在弥合认知和表达之间的鸿沟
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
第四范式“式说”大模型入选《2025年通用人工智能创新应用案例集》
“图壤·阅读元宇宙”亮相北京国际图书博览会
【|直播|预告】人工智能高峰论坛将于7月2日13:30准时开播!
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
微软 Copilot 团队主管呼吁用户与 AI 交流时应使用恰当的礼貌用语
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
AI技术改变*,新骗局来袭,*成功率接近100%
应用生成式人工智能技术改善农业产业
OpenAI夺冠:人工智能为云计算带来新变革
世界水下机器人大赛:9国青年携手逐梦深蓝
美图公司影像节或发布AI设计新品
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
中兴通讯无人机高空基站助力北京门头沟受灾乡镇保障应急通信
中国联通推出“极光一号”5G机载终端,适配大疆等品牌无人机设备
脑机接口产业联盟发布十大脑机接口关键技术
周鸿祎:360智脑开放API接口 AI大模型将赋能百行千业
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
微软Bing聊天机器人电脑端即将支持语音提问
马斯克回应“人工智能让一切变得更好”:我们已经是半机器人了
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
AI生成新闻网站数量激增,正在疯狂赚取广告收入
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
遵义市首次引入手术机器人,成功实施全膝关节置换术
你们的开机第一屏画面要变了!安卓机器人首次3D化
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
衡水市冀州中学机器人社团在世界机器人大赛中斩获佳绩
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
万兴播爆桌面端上线,支持AI数字人搜索、视频编辑等功能
实现人工智能和物联网的协同运作
给小朋友最好的科技礼物:乐天派桌面机器人
2025-07-16

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 ias (bool: If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos if self.use_rel_pos: # initialize relative positional embeddings
self.rel_pos_h = add_parameter(self,paddle.zeros((2 * input_size[0] - 1, head_dim)))
self.rel_pos_w = add_parameter(self,paddle.zeros((2 * input_size[1] - 1, head_dim))) if not rel_pos_zero_init:
trunc_normal_(self.rel_pos_h)
trunc_normal_(self.rel_pos_w) def forward(self, x):
B, H, W, _ = x.shape # qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape((B, H * W, 3, self.num_heads, -1)).transpose((2, 0, 3, 1, 4)) # q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape((3, B * self.num_heads, H * W, -1)).unbind(0)
attn = (q * self.scale) @ k.transpose((0, 2, 1)) if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = F.softmax(attn,axis = -1)
x = (attn @ v).reshape((B, self.num_heads, H, W, -1)).transpose((0, 2, 3, 1, 4)).reshape((B, H, W, -1))
x = self.proj(x) return xclass Block(nn.Layer):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=True,
drop_path=0.0,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU,
use_rel_pos=False,
rel_pos_zero_init=True,
window_size=0,
use_residual_block=False,
input_size=None, ):
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
drop_path (float): Stochastic depth rate.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then not
use window attention.
use_residual_block (bool): If True, use a residual block after the MLP block.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.norm1 = norm_layer(dim,epsilon = 1e-6)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
self.window_size = window_size
self.use_residual_block = use_residual_block if use_residual_block: # Use a residual block with bottleneck channel as dim // 2
self.residual = ResBottleneckBlock(
in_channels=dim,
out_channels=dim,
bottleneck_channels=dim // 2,
norm="LN",
act_layer=act_layer,
) def forward(self, x):
shortcut = x
x = self.norm1(x) # Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x) # Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) if self.use_residual_block:
x = self.residual(x.transpose((0, 3, 1, 2))).transpose((0, 2, 3, 1)) return x
ias (bool: If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos if self.use_rel_pos: # initialize relative positional embeddings
self.rel_pos_h = add_parameter(self,paddle.zeros((2 * input_size[0] - 1, head_dim)))
self.rel_pos_w = add_parameter(self,paddle.zeros((2 * input_size[1] - 1, head_dim))) if not rel_pos_zero_init:
trunc_normal_(self.rel_pos_h)
trunc_normal_(self.rel_pos_w) def forward(self, x):
B, H, W, _ = x.shape # qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape((B, H * W, 3, self.num_heads, -1)).transpose((2, 0, 3, 1, 4)) # q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape((3, B * self.num_heads, H * W, -1)).unbind(0)
attn = (q * self.scale) @ k.transpose((0, 2, 1)) if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = F.softmax(attn,axis = -1)
x = (attn @ v).reshape((B, self.num_heads, H, W, -1)).transpose((0, 2, 3, 1, 4)).reshape((B, H, W, -1))
x = self.proj(x) return xclass Block(nn.Layer):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=True,
drop_path=0.0,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU,
use_rel_pos=False,
rel_pos_zero_init=True,
window_size=0,
use_residual_block=False,
input_size=None, ):
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
drop_path (float): Stochastic depth rate.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then not
use window attention.
use_residual_block (bool): If True, use a residual block after the MLP block.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.norm1 = norm_layer(dim,epsilon = 1e-6)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
self.window_size = window_size
self.use_residual_block = use_residual_block if use_residual_block: # Use a residual block with bottleneck channel as dim // 2
self.residual = ResBottleneckBlock(
in_channels=dim,
out_channels=dim,
bottleneck_channels=dim // 2,
norm="LN",
act_layer=act_layer,
) def forward(self, x):
shortcut = x
x = self.norm1(x) # Window partition
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
x = self.attn(x) # Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) if self.use_residual_block:
x = self.residual(x.transpose((0, 3, 1, 2))).transpose((0, 2, 3, 1)) return x