本文复现论文提出的MetaHeac模型,基于PaddlePaddle 2.3.0框架,在腾讯Look-alike数据集上进行,解决look-alike建模挑战,复现AUC达0.7112,还介绍了数据集、环境、步骤、代码结构及复现心得。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在推荐系统和广告平台上,营销人员总是希望通过视频或者社交等媒体渠道向潜在用户推广商品、内容或者广告。扩充候选集技术(Look-alike建模)是一种很有效的解决方案,但look-alike建模通常面临两个挑战:(1)一家公司每天可以开展数百场营销活动,以推广完全不同类别的各种内容。(2)某项活动的种子集只能覆盖有限的用户,因此一个基于有限种子用户的定制化模型往往会产生严重的过拟合。为了解决以上的挑战,论文《Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising》提出了一种新的两阶段框架Meta Hybrid Experts and Critics (MetaHeac),采用元学习的方法训练一个泛化初始化模型,从而能够快速适应新类别内容推广任务。
MetaHeac训练流程如下: 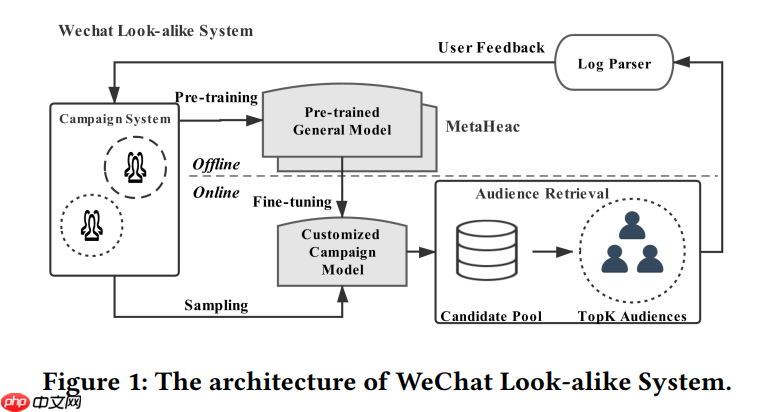
模型核心结构如下: 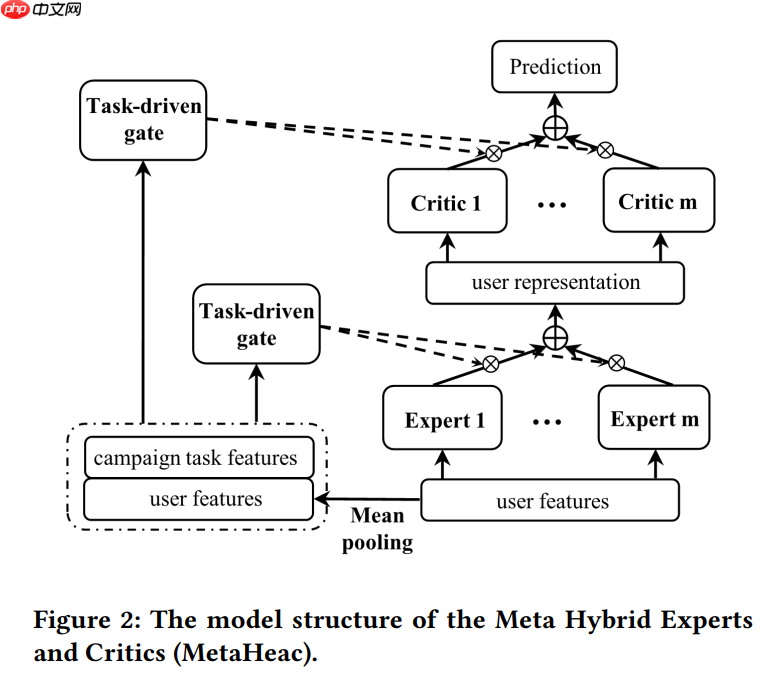
为了复现文献中的实验结果,本项目基于paddlepaddle深度学习框架,并在Lookalike数据集上进行训练和测试。
论文 :
项目参考 : https://github.com/easezyc/MetaHeac
基于paddlepaddle深度学习框架,对文献MetaHeac进行复现后,测试精度如下表所示。
| 模型 | auc | batch_size | epoch_num | Time of each epoch |
|---|---|---|---|---|
| MetaHeac | 0.7112 | 1024 | 1 | 3个小时左右 |
超参数配置如下表所示:
| 超参数名 | 设置值 |
|---|---|
| batch_size | 1024 |
| task_count | 5 |
| global_learning_rate | 0.001 |
| local_test_learning_rate | 0.001 |
| local_lr | 0.0002 |
本项目使用的是Tencent Look-alike Dataset,该数据集包含几百个种子人群、海量候选人群对应的用户特征,以及种子人群对应的广告特征。出于业务数据安全保证的考虑,所有数据均为脱敏处理后的数据。本次复现使用处理过的数据集,直接下载propocessed data。
数据集链接: https://paddlerec.bj.bcebos.com/datasets/lookalike/Lookalike_data.rar
 Openflow
Openflow
一键极速绘图,赋能行业工作流
 88
查看详情
88
查看详情

# step1: 确认您当前所在目录为PaddleRec/models/multitask/metaheac %cd PaddleRec/models/multitask/metaheac
/home/aistudio/PaddleRec/models/multitask/metaheacIn [ ]
# step2: 进入paddlerec/datasets/目录下,执行该脚本,会从国内源的服务器上下载我们预处理完成的Lookalike全量数据集,并解压到指定文件夹。%cd ../../../datasets/Lookalike !sh run.shIn [ ]
# step3: train%cd ../../models/multitask/metaheac/ !python -u ../../../tools/trainer.py -m config_big.yamlIn [ ]
# step4: infer 此时test数据集为hot!python -u ./infer_meta.py -m config_big.yamlIn [ ]
# step5:修改config_big.yaml文件中test_data_dir的路径为cold!python -u ./infer_meta.py -m config_big.yaml
config_big.yaml配置文件中参数如下:
| 参数选项 | 默认值 | 说明 |
|---|---|---|
| --batch_size | 1024 | 训练和测试时,一个batch的任务数 |
| --task_count | 5 | 子任务类别数 |
| --global_learning_rate | 0.001 | 全局更新时学习率 |
| local_test_learning_rate | 0.001 | 测试时学习率 |
| local_lr | 0.0002 | 局部更新时学习率 |
| embed_dim | 64 | 嵌入向量的维度 |
| mlp_dims | [64, 64] | 全连接层的维度 |
| num_expert | 8 | 专家数量 |
| num_output | 5 | 批评者数量 |
├── data #样例数据
├── train #训练数据
├── train_stage1.pkl
├── test #测试数据
├── test_stage1.pkl
├── test_stage2.pkl
├── net.py # 核心模型组网├── config.yaml # sample数据配置├── config_big.yaml # 全量数据配置├── dygraph_model.py # 构建动态图├── reader_train.py # 训练数据读取程序├── reader_test.py # infer数据读取程序├── readme.md #文档
为了测试模型在不同规模的内容定向推广任务上的表现,将数据集根据内容定向推广任务给定的候选集大小进行了划分,分为大于T和小于T两部分。将腾讯广告大赛2018的Look-alike数据集中的T设置为4000,其中hot数据集中候选集大于T,cold数据集中候选集小于T.
infer_meta.py是用于元学习模型infer的tool,在使用中主要有以下几点需要注意:
基于论文开源的代码实现基于Paddle的代码还是比较简单的,但是模型组网成功后,精度与原论文精度相差很大。 很可能是模型在前向传播时就已经出现问题了,建议基于官方提供的reprod_log,与参考代码进行一步步的 前向对齐,才能保证模型组网万无一失。
前向对齐,才能保证模型组网万无一失。
在本项目复现时,遇到最大的问题是前向对齐时的误差很小,但是无论如何第一轮的loss就是对不齐。找了很久问题,最后直接将参考代码的初始化参数加载到paddle复现的模型上,成功跑出了原论文精度,所以如果前向没大问题,也有可能是模型初始化参数的问题,可以设置下随机种子和加载可复现的初始化参数。
由于元学习训练方式与传统训练方式有所区别,所以要单独写train和infer的数据读取。细节部分在infer_meta.py说明中有提到,主要是关掉dataloader默认的组batch方式,自己写组batch。
| 信息 | 说明 |
|---|---|
| 发布者 | 宁文彬 |
| 时间 | 2025.06 |
| 框架版本 | Paddle 2.3.0 |
| 应用场景 | 元学习 |
| 支持硬件 | GPU、CPU |
以上就是【论文复现赛】第六期冠军项目-MetaHeac-推荐系统的详细内容,更多请关注其它相关文章!
# git
# 谷歌推广网站教程图片大全
# 网站 后台 优化
# 营销推广途径不包括
# 涉县网络推广营销工作
# 滁州推荐网站优化
# seo 标题逗号
# 官网
# 所示
# 在对
# 测试数据
# 加载
# 腾讯
# 第六期
# 一言
# 前向
# 中文网
# fig
# looka
# udio
# 区别
# bing
# ai
# python
# seo教学视频外推
# 原州区门户网站优化
# 衡阳seo关键词排名
# 武侯区网站建设服务公司
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
百度创始人、董事长兼首席执行官李彦宏:AI原生应用比大模型数量更重要
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
【机智云物联网低功耗转接板】远程环境数据采集探索
人工智能行业急缺人 AI人才年薪能达近42万元
500元一张的AI艺术二维码制作,详细教程来了!
视觉中国推出AI灵感绘图功能
电力人工智能数据集目录首次发布
今年,全球客服中心支出将增长 16.2%,迎接对话式 AI 的浪潮,根据 Gartner 报告
掌阅科技入选北京市通用人工智能产业创新伙伴计划第二批成员名单
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
人工智能正在弥合认知和表达之间的鸿沟
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
借力AI!PCB全球巨头,有爆发潜质吗?
微软 GitHub Copilot 编程助手被投诉:换口吻改写公共代码来躲版权
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
城市在采用人工智能方面进展如何?
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
高质量数据推动AI场景化应用快速发展及落地
【|直播|预告】人工智能高峰论坛将于7月2日13:30准时开播!
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
华为HarmonyOS 4:享流畅提升20%,AI大模型更智能一览无余
Vision Pro头显重磅发布;苹果收购AR厂商Mira
网易加速行业AI大模型应用,将覆盖100多个应用场景
华为HarmonyOS 4将集|成人|工智能大型模型
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
优地网络助力新媒体拥抱人工智能时代
杀入生成式AI的亚马逊云科技,能否再次生成未来?
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
Moka AI产品后观察:HR SaaS迈进AGI时代
比尔盖茨:AI确实存在风险,但可控
Valve Index VR 头显销量下滑,上市四年的长青树渐失光彩
清华&中国气象局大模型登Nature:解决世界级难题,「鬼天气」预报时效首次达3小时
“痴迷”元宇宙,魔珐科技想做什么?
借助ChatGPT快速上手ElasticSearch dsl
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
机器人 展才能
Meta将VR头显最低年龄限制从13岁降至10岁
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
鸿蒙OS 4将实现AI大模型集成,余承东表示坚持AI辅助而非AI取代
应对算力挑战,亚马逊云科技发力AI基础设施建设
腾讯机器狗进化:通过深度学习掌握自主决策能力
华为发布大模型时代AI存储新品
智能技术提高现代商业运营的7七种方式
Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
英特尔张宇:边缘计算在整个AI生态系统中扮演重要角色
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
2025-08-01

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
